有人预测GPT (有人预测甘肃地震吗)

不久前,谷歌发布基于他们最新一代人工智能架构Pathways研发的 5400 亿参数大模型——PaLM,具备标记因果关系、上下文理解、推理、代码生成等等多项功能,其中常识推理能力更是较以往的语言模型有较大提升。
但同时,大家也一如既往地注意到 PaLM 的计算成本:用了6144块TPU。如果租显卡训练,最高花费可能达到1700万美元(人民币超过1个亿,“一个小目标”)。
显然,这很烧钱,不符合“经济可用”的原则。难怪业内人士常常吐槽:苦大模型久矣。
如果模型往大走,一个劲地砸钱,何时是个尽头?有学者也向AI科技评论表示:类似PaLM这样的大模型在结果上确实取得了不错的突破,但训练与计算的成本非常高,没必要将许多任务拼在一起。
对于大模型的未来发展,GPT系列或许能提供一些新的见解。
近日,Cambrian AI的分析师Alberto Romero便发表了一篇文章,基于OpenAI首席执行官Sam Altman在数月前的说法,推测GPT-4即将在今年7月到8月发布,并基于Altman在去年的一场问答,对GPT-4的特征进行了预测。
可以肯定的是,Altman称,GPT-4的参数不会达到100T。
Alberto Romero也猜测,或许GPT-4的规模会比GPT-3略大,但“大”不会像GPT-3一样成为GPT-4的“卖点”。相反,OpenAI更致力于如何让规模较小的模型发挥更大的性能。
首先,Alberto判断,GPT-4不会是最大的语言模型。Altman也称它不会比GPT-3大很多。与前几代的神经网络相比,GPT-4肯定会很大,但大小不会是它的显著特征。GPT-4可能介于GPT-3和Gopher (175B-280B)之间。
接着,Alberto给出了他预测的理由:
去年由英伟达和微软开发的Megatron-Turing NLG有530B参数,一直是最大的密集神经网络——其大小已是GPT-3的3倍——直到最近出现了谷歌的PaLM,其大小为540B。但值得注意的是, MT-NLG之后的一些较小的模型达到了更高的性能水平。
也就是说,更大 ≠ 更好。小型模型的存在有两个意义。
其一是,企业已经意识到, 要改善性能,扩大模型的规模不是唯一的方法,也不是最好的方法。 当增加的计算预算主要分配到增加参数的数量上时,性能的提高是最显著的,并且遵循幂律关系。 谷歌、英伟达、微软、OpenAI、DeepMind和其他开发语言模型的公司从表面上看接受了这一指导原则。

MT-NLG虽然规模很大,但在性能方面并不是最好的。事实上,它在任何单一类别基准上都不是最好的存在。像Gopher (280B)或Chinchilla (70B)这种更小的模型——哪怕仅仅是其一小部分——在任务上的表现都比MT-NLG好得多。
第二个意义是,公司开始拒绝“越大越好”的教条。虽然增加参数很简单,但是拥有更多参数只是众多可以提高性能的因素之一,而附带损害(如碳足迹、计算成本或进入死路)反而使其成为最糟糕的因素之一。如果企业能够从一个较小的模型中获得类似或更好的结果时,在构建一个庞大的模型之前就会三思而后行。
他们不再专注于制造非常大的模型,而是致力于让较小的模型发挥最大的作用。 OpenAI的研究人员是缩放假设(scaling hypoThesis)早期的倡导人,但现在他们可能已经意识到其他还没走过的路可以改进模型。
相比将GPT-4做大,Alberto更倾向于认为,OpenAI会将把重点转移到其他方面——比如 数据、算法、参数化或对齐 ——这些因素可以更显著地改进模型。
当涉及到优化时,语言模型会遇到一个关键的问题。训练如此昂贵,以至于企业不得不在准确性和成本之间做出权衡。而这种抉择常常会导致模型明显未优化。
GPT-3只被训练了一次,仍有一些错误,这些错误在某些情况下可能会导致重新训练。由于成本太高、负担不起,OpenAI决定不进行优化,而这使得研究人员无法找到模型的最佳超参数集(例如学习速率、批尺寸、序列长度等)。
训练成本很高导致的另一个后果是模型行为的分析受到限制。 当Kaplan的团队总结出模型大小是提高性能最相关的变量时,他们没有考虑到训练令牌的数量——也就是输入模型的数据量。这样做将需要大量的计算资源。
科技公司遵循Kaplan的结论,因为这已是他们所知最好的想法。讽刺的是,正是受到经济限制的影响,谷歌、微软、Facebook和其他公司在越来越大的模型上“浪费”了数百万美元,并且在这个过程中产生了大量的污染。
现在,以DeepMind和OpenAI为首的公司正在探索其他方法。 他们试图找到最优模型,而不仅仅是更大的模型。
如果使用最优超参数训练模型,GPT-3可以得到进一步的改进。 他们发现,6.7B版GPT-3的性能提高了很多,可以与最初的13B版GPT-3媲美。超参数调优(对于较大的模型来说不可行)赋予的性能提升相当于参数数量增加了一倍。
他们发现了一种新的参数化(μP),在这种参数化中,小型模型的最佳超参数也同样适用于同类大型模型。μP使他们能够优化任意大小的模型,而且只需花费很小一部分的培训成本。然后这些超参数可以几乎不花钱地转移到更大的模型中。
几周前,DeepMind重新审视了Kaplan的发现,并意识到 训练令牌的数量与模型大小一样影响性能, 而这与人们的看法相反。他们的结论是,随着更多的计算预算可用,应该将其平均分配给可缩放参数和数据。他们通过训练Chinchilla来证明自己的假设,Chinchilla是一个70B模型(是曾经的SOTA,比Gopher小4倍),它使用的数据是GPT-3 (1.4T令牌-来自典型的300B)以来所有大型语言模型的4倍。
结果是明确的。在许多语言基准测试中,Chinchilla“一致且显著地”优于Gopher、GPT-3、MT-NLG和所有其他语言模型,而目前的模型有过大的问题,且训练不足。
考虑到GPT-4将略大于GPT-3,根据DeepMind的发现,GPT-4需要达到计算优化的训练令牌数量将约为5万亿,比当前的数据集高出一个数量级。他们需要训练模型以达到最小训练损失的失败次数,将比他们使用GPT-3(使用Gopher的计算预算作为代替)时多10 - 20倍。
Altman在问答中说GPT-4将比GPT-3使用更多的计算时,可能就是在指这一点。
OpenAI肯定会对GPT-4进行优化相关的调查——尽管具体到什么程度还无法预测,因为他们的预算是未知的。可以肯定的是,OpenAI将专注于优化除模型大小之外的其他变量。找到超参数的最佳集合,最优计算模型大小和参数的数量可以在所有基准测试中带来难以置信的改进。如果将这些方法合并到一个模型中,那这个模型将会达到一个所有预测都难以想象的高度。
Altman还说,如果不把模型做大,人们就不会相信模型能有多好。他可能是指扩大模型尺寸的工作目前已经结束。
深度学习的未来是多模态模型。人类的大脑有多种感觉,这是因为我们生活在一个多模态的世界。每次只以一种模式感知世界,极大地限制了人工智能处理或理解世界的能力。
然而,良好的多模态模型比良好的仅用语言或仅用视觉的模型要难得多。将视觉信息和文本信息组合成单一的表示形式是一项艰巨的任务。我们对大脑是如何做到这一点的了解非常有限(并不是说深度学习社区考虑了认知科学对大脑结构和功能的见解),所以我们不知道如何在神经网络中实施。
(像DALL·E或LaMDA那样),而是一个纯文本模型。因此,Alberto的猜测是, 在跳到下一代多模态人工智能之前,他们试图通过对模型和数据集大小等因素进行调整来达到语言模型的极限。
稀疏模型利用条件计算,使用模型的不同部分处理不同类型的输入。稀疏模型最近取得了巨大的成功,其可以很容易地扩展到超过1T参数标记,而不会产生高额的计算成本,能够在模型大小和计算预算之间创建一个看似正交的关系。然而,MoE方法的好处在非常大的模型上就没那么多了。
考虑到OpenAI关注密集语言模型的历史,Alberto认为,GPT-4大概率也将是一个密集模型。又因为Altman说GPT-4不会比GPT-3大很多,我们可以得出结论,稀疏性不是OpenAI的选择——至少目前是这样。
OpenAI在解决AI对齐问题上投入了大量的精力:如何让语言模型遵循我们的意图并坚持我们的价值观——不管这到底意味着什么。这不仅是一个数学难题(例如,我们如何让人工智能准确理解我们想要的东西?),而且也是一个哲学难题(比如没有一种通用的方法可以让人工智能与人类保持一致,因为人类价值观在不同群体之间的差异是巨大的,而且常常互相冲突)。
他们使用InstructGPT进行了第一次尝试,这是一种通过人类的反馈来学习遵守指令的新GPT-3(不管这些指令是出于好意还是恶意,都没有被纳入模型中)。
InstructGPT的主要突破在于,不管其在语言基准上的结果如何,其都被人类评审认为是一个更好的模型(这些评审是一个由OpenAI员工和英语人士构成的同质的群体,所以我们应该对得出的结论保持谨慎的态度)。这显著表明,我们有必要克服把基准作为评估人工智能能力的唯一指标。人类如何感知这些模型可能同样重要,如果不是更重要的话。
考虑到Altman和OpenAI要遵守作为一个有益AGI的承诺,我相信GPT-4将实现并构建他们从InstructGPT中获得的发现。
我认为他们将改进对齐模式的方式,因为目前为这个模型制作标签的仅限于OpenAI员工和英语人士。而真正的对齐应该包括各种性别、种族、国籍、宗教等方面群体。这是一个巨大的挑战,朝着这个目标迈进的任何一步都将受到大众的欢迎。
模型大小:GPT-4将比GPT-3大,但与目前最大的模型(MT-NLG 530B和PaLM 540B)相比不是很大。模型规模不会是一个显著的特征。
最优性:GPT-4将比GPT-3使用更多的计算。GPT-4 将实现对参数化(最优超参数)和比例法则(训练令牌的数量与模型大小同样重要)的新优化见解。
,而不是多模态模型。OpenAI希望在完全跳到像DALL·E这样的多模态模型之前先充分利用好语言模型。
稀疏性:按照GPT-2和GPT-3的趋势,GPT-4将是一个 (所有参数将用于处理任何给定的输入)。在未来,稀缺性将变得更加重要。
对齐:GPT-4将比GPT-3更对齐,其将从InstructGPT进行学习,而InstructGPT是根据人类的反馈进行训练的。不过,人工智能的对齐还有很长的路要走,我们应该仔细评估所做出的工作,而不应该对此进行炒作。

版权文章,未经授权禁止转载。详情见 转载须知 。

本文地址: http://www.gpxz.com/article/06e06e4ba23bf6fa2632.html


站长之家提供网站综合信息查询,包括搜索引擎收录查询,反向链接查询,Alexa排名查询,PR查询,IP地址查询,WHOIS查询,域名注册查询,过期域名查询等站长工具。
货捕头(杭州女装网)是专业的女装批发一件代发货源平台。货捕头(杭州女装网)整合了杭州四季青女装、广州女装、织里童装、虎门女装等服装批发市场数万档口和服装厂的新款一手服装货源,为全国电商卖家、网红直播、微商和服装店主提供了极具性价比的女装批发货源以及方便快捷的一件代发服务,找服装货源及女装批发代理首选货捕头杭州女装网。

娱乐交流社区

北京市东昌汇丰钢管有限公司{139-1103-9958}常年销售天津、包钢、宝钢、冶钢、成都、鞍钢、衡阳等厂家的无缝钢管及合金管。产品有:高压合金管、高压锅炉管、GB9948石油裂化管、GB6479化肥专用管。

郑州慧泽生化科技有限公司
第33届中国国际建筑装饰展")
2024深圳建材展,第33届中国国际建筑装饰展,将于2024年12月12-14日在深圳国际会展中心盛大开展,来自多个省会与国家近千家企业协同1800个建筑装饰材料,深圳建筑装饰材料展,铝材及门窗幕墙展,机器人与自动化展,锁具安防展,照明展,深圳卫浴展,深圳家具展,酒店工程展,酒店建筑展,酒店装饰展,深圳商业空间展,轴承专用装备,包装设备,激光机械,激光设备行业品牌齐聚,最新技术和产品,打造极具影响力的展贸平台及全球最大酒店,建材交易盛会,吸引专业采购商达50万人次!
有限公司")
新夷仪器科技(上海)有限公司,Triplets仪器,8站比表面仪,真密度分析仪,真密度测试仪,化学吸附,接触角分析仪,激光粒度仪,液氮泵,开闭孔率测试

潮州市潮安区金梅不锈钢制品有限公司

山东邦泰节能科技有限公司研发生产不锈钢冷却塔,水轮机冷却塔,无动力节能冷却塔,全钢冷却塔,玻璃钢冷却塔.13656464488

诗词学会,诗词名句,古诗词,汉语字典查字,在线汉语词典,汉语字词大全

河南至善文化发展公司11年专注河南校园文化设计建设服务,专业从事河南校园文化建设,河南导视系统设计,商业空间设计,党建文化主题公园设计制作安装售后于一体.15981825118.

石家庄新闻网,省会中心城市新闻门户,石家庄对外宣传的主流媒体,石家庄市唯一一家拥有国新办新闻发布资质的国家重点地方新闻网站,石家庄日报、燕赵晚报、精品导报、燕赵老年报四报电子版的发布平台。新闻更新量最大、点击量最高的地方新闻网站。30多个独立频道、二百多个新闻栏目,上百个专题数据库。可在40多个省会中心城市的国家重点新闻网站链接本网。


最近迷宫类型的游戏受到了众多玩家的关注,下面给大家带来的一个小女孩走立体迷宫的游戏叫什么2022,由于九游目前还没有收录女孩子走迷宫的游戏,所以下面小编给大家介绍几款非常好玩的迷宫游戏,感兴趣的小伙伴们可以和小编一起来看看,1、,3D走出迷宫,这是一款由3D技术构建的迷宫类游戏,游戏的画面十分的逼真,同时游戏的场景丰富,在游戏中玩家们...。

西式的餐饮来到了的餐饮市场有些年数了,在内地的市场有着很稳定的消费群体,其中就包扩了汉堡的开设,在有着很潮流的引导作用,汉堡店的形式也是千变万化的,乐而美汉堡的开设就有着很高的人气,在国内的很多的地区都有该快餐品牌店铺的开设,已经形成了特有的加盟品牌的形象,目前在全国各地都在诚招加盟商代理商,不少的加盟商就会考虑加盟乐而美汉堡好吗,快...。
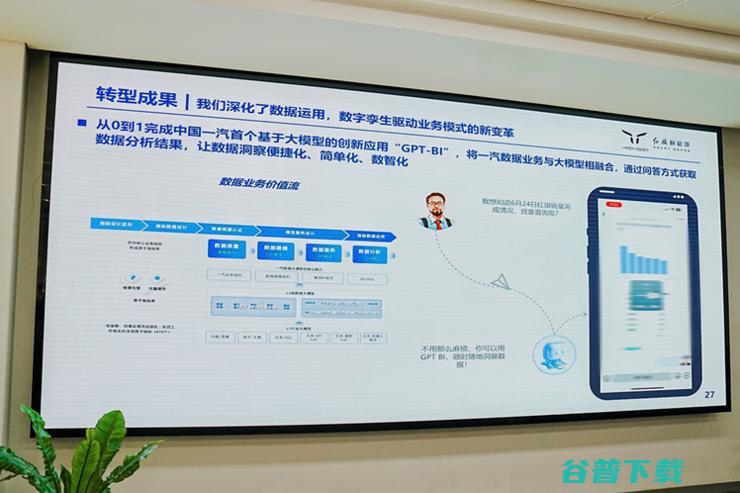
1月22日,由中国一汽联合阿里云通义千问打造的大模型应用GPT,BI率先落地,为中国一汽的数字化转型升级增添新活力,该应用可接收自然语言查询,结合企业数据自动生成分析图表,目前可达到近90%的准确率,更值得一提的是,相比传统BI,BusinessIntelligence,的,固定问答,,它能实现问答任意组合,数据随时穿透,做到,问答即...。

随着新一轮人口出生高峰期的到来,母婴市场将会进一步扩大,面对这样一个万亿蓝海,很多创业者都萌发了开育婴店的想法,可是新手开店并不容易,怎样开育婴店呢,这个问题难倒了不少人,下面小编就来给出明确的答案,希望能给想争取进一步拓展市场的有识之士提供一定的帮助,怎样开育婴店,想要成功地把育婴店开起来,有三个步骤是非常关键的,缺一不可,具体如下...。

发表在专业问答2023,12,1910,06展示机型信息,品牌型号,当贝X5系统版本,当贝OS4.0软件版本,电视家3.0电视家暂停服务是因为没有网络电视直播的版权,因此涉及侵权问题,导致电视家被要求整改,进行了暂停服务处理,如果要看电视直播,还是需要使用正规的电视直播软件或者外接IPTV电视盒子,电视家暂停服务怎么回事电视家暂停服务...。
举办时间,2011,5,26,2011,5,28举办展馆,北京会议中心北京市朝阳区天辰东路7号乘车路线所属行业,绿色环保展会面积,16500平方米主办单位,洗涤用品工业协会国际贸易促进委员会轻工行业分会农业机械工业协会植保与清洗机械分会承办单位,北京创智国际会展有限公司展会规模,预计展览面积15000平方米2011国际清洁产业博览...。

没有公开犯罪事实,只知道他与当地发生的重大刑事案件有关,鹤岗警方悬赏30万抓捕犯罪嫌疑人,但对犯罪嫌疑人的犯罪事实并没有公开在悬赏通告中,只是说这名犯罪嫌疑人与当地发生的重大刑事案件有关,悬赏30万进行追捕,而且公开了他的身份信息和特征,根据悬赏公告中提供的信息,可以知道犯罪嫌疑人年龄62岁,长方形走入公腰,而且习惯带鸭舌帽,并且是东...。

去朋友公司谈点事儿,说了没几句他说有事儿让我等会儿,然后抄起一摞纸箱子就下楼了,从窗户往下看,一个老太太站在楼底下,旁边一堆纸壳本儿,朋友过去就抢,抢完了就往自己车上扔,我看看旁边他的员工们,他们发出了开头儿的感叹,说老板今年真不容易,这买卖太难做了,...。

曝高通骁龙X1P-42-100处理器基于Purwa核心,内存位宽64bit,内存,八核,处理器,电池容量,64bit,高通骁龙x1

7月11日,中共中央政治局委员、外交部长王毅同荷兰新任外交大臣费尔德坎个别电话,就北约华盛顿峰会对中国启动无故指摘,王毅表态称,中方绝不接受,王毅示意,在敌对与安保疑问上,中国是环球上纪录最好的大国,一直是国际社会中的敌对力气、稳固力气,中国同北约国度政治制度、价值理念不同,但这不应成为北约怂恿同中国反抗的理由,正确之道是增强对话,增...。

开关门,开关门如何,什么开关门,哪些开关门,怎么开关门

《骑马与砍杀:战团》是一款备受期待的独立资料片,它通过栩栩如生的骑马战斗和详细的战斗系统向玩家重现了中世纪的战场。完美下载为您准备了“《骑马与砍杀:战团》免安装中文破解版”,欢迎大家前来下载使用

京东618第一个小时销售额同比增长超250%6月18日零点,京东全民年中购物节拉开了高潮的序幕,第一个小时的销售额超过去年同期的250%,京东集团董事局主席兼首席执行官刘强东第一个在朋友圈透露了这一消息,3C领域大量品类迅速突破了亿元销售额,电脑办公品类只用了2分50秒,数码品类用了5分30秒,手机品类用时3分07秒,其中手机在一小时...。
最近大家都很兴奋,ChatGPT的出现带火了知识博主,增加了变现机会,很多人都在讨论LLM和AIinfra,如何写诗如何画画,真正讨论应用的很少,讨论行业应用的就更少了,但是看了YC去年的List后觉得AI,Native应用的前景已经非常明朗了,AI已经深入寻常百姓家,这个普世的转变,对产品经理来说更是一个设计产品范式的根本性转变,而...。

雷锋网AI科技评论按,近日,TheAtlantic记者DEREKTHOMPSON应邀走进了GoogleX,并对其进行了专题报道,揭密了GoogleX的创新哲学,雷锋网AI科技评论编辑在不改变原意的基础上做了整理,I.从问题开始一位蛇形机器人设计师、一名热气球科学家、一名液晶技术专家、一位异次元物理学家、一个心理学怪胎、一位电子材料方面...。

智能手机战场,已经升起5G的烽烟,一方面,三星、华为、小米、OPPO、vivo等主流玩家都各出其招,要么自主研发,要么借用产业链的力量,已经推出了多款可商用的5G智能手机;另一方面,在这些动作的背后,与智能手机厂商关系最为密切的5G基带市场也是风云再起,高通、三星、华为、联发科等几大基带玩家也是动作频频——就连对5G不动声色的苹果,也...。

雷锋网按,本文译自HITConsultant,作者为SignifyResearch总监AlexGreen,近日,SignifyResearch公布了2018年全球电子病历与EHR,电子健康记录,市场报告,报告显示,电子病历与EHRIT在EMEA,欧洲、中东、非洲,市场份额大约为37亿美元,其中只有Cerner公司这一家供应商的市场占有...。
