神经机器翻译的混合交叉熵损失函数 (神经机器翻译的单词错误减少了)

本文提出了一个新的损失函数,混合交叉熵损失(), 用于替代在机器翻译的两种训练方式(Teacher forcing和 Scheduled Sampling)里常用的交叉熵损失函数(CE)
,计算开销基本和标准的CE持平,并且在多个翻译数据的多种测试集上表现优于CE。这篇文章我们简要介绍Mixed CE的背景和一些主要的实验结果。
本节简单介绍一下 Teacher Forcing 和 Scheduled Sampling 的背景。
Teacher Forcing[1]训练方式指的是当我们在训练一个自回归模型时(比如RNN,LSTM,或者Transformer的decoder部分), 我们需要将真实的目标序列(比如我们想要翻译的句子)作为自回归模型的输入,以便模型能够收敛的更快更好。 通常在Teacher Forcing(TF)这种训练方式下,模型使用的损失函数是CE:

值得注意的是,机器翻译(MT)本身是一个一对多的映射问题,比如同样一句中文可以翻译成不同的英文,而使用CE的时候,因为每个单词使用一个one-hot encoding去表示的,这种情况下MT是被我们当作了一个一对一的映射问题。这种方式可能会限制模型的泛化能力,因为使用CE的模型学到的条件分布
 更接近于一个one-hot encoding,而非数据真实的条件分布
更接近于一个one-hot encoding,而非数据真实的条件分布
 。但不可否认的是,即使模型用CE训练,它在实践中也取得了很好的效果。CE在实践中的成功意味着模型学习到的条件分布
。但不可否认的是,即使模型用CE训练,它在实践中也取得了很好的效果。CE在实践中的成功意味着模型学习到的条件分布
 可能也包含着部分真实分布
可能也包含着部分真实分布
 的信息。我们能不能在训练的时候从 提取
的信息。我们能不能在训练的时候从 提取
 的信息呢?这就是我们的Mixed CE所要完成的目标。
的信息呢?这就是我们的Mixed CE所要完成的目标。
虽然TF训练方式简单,但它会导致exposure bias的问题 ,即在训练阶段模型使用的输入来自于真实数据分布,而在测试阶段模型每一时刻使用的输入来自于模型上一时刻的预测结果,这两个输入分布之间的差异被称作exposure bias。
因此,研究者们进而提出了Scheduled Sampling[2](SS)。 在自回归模型每一时刻的输入不再是来自于真实数据,而是随机从真实数据或模型上一时刻的输出中采样一个点作为输入。 这种方法的本质是希望通过在训练阶段混入模型自身的预测结果作为输入,减小其与测试阶段输入数据分布的差异。也就是说,SS所做的是让训练输入数据分布近似测试输入数据的分布,从而减轻exposure bias。
而另一种减轻exposure bias的思想是,即使训练和测试阶段输入来自不同的分布,只要模型的输出是相似的,这种输入的差异性也就无关紧要了。我们的Mixed CE就是想要达到这样的目标。
需要注意的一点是,SS本来是用于RNN的,但由于Transformer的兴起,后续的研究者们提出了一些改进的SS以便适用于Transformer decoder在训练阶段能够并行计算的特性。即运行Transformer deocder两次,第一次输入真实的数据
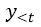 ,然后从t时刻的输出分布里采样一个数据点
,然后从t时刻的输出分布里采样一个数据点
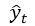
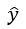 。接着,将
。接着,将
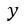 里面的元素随机进行混合,得到新序列
里面的元素随机进行混合,得到新序列
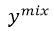 作为decoder的输入,按照正常方式进行训练。
作为decoder的输入,按照正常方式进行训练。
我们提出的Mixed CE可以同时用于TF和SS两种训练方式中。
在TF中,为了应用MixedCE,我们首先做出一个假设: 如果模型当前预测的概率最大的token和目标token不一致,那我们认为预测的token很有可能是目标token的同义词或者同义词的一部分。
我们做出这个假设是因为在实际中的平行语料库里,同样一个源语言的单词在目标语言会有多种不同的翻译方式。如果这些不同的翻译在语料库里出现的频率相差不多,那么在预测该源语言单词时,模型非常有可能给这些不同的翻译相似的概率,而概率最大的那种翻译方式恰好是目标token的同义词。
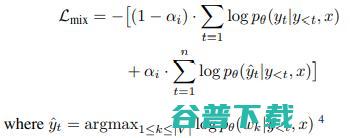
是模型在当前时刻模型预测的最有可能的结果,而根据我们之前的假设,
的同义词。Mixed CE通过以
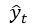 作为目标进行优化,有效利用了
作为目标进行优化,有效利用了


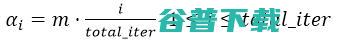
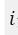 是当前训练的iteration,total_iter代表了总的训练轮数。随着训练的进行,模型的效果越来越好,
是当前训练的iteration,total_iter代表了总的训练轮数。随着训练的进行,模型的效果越来越好,
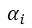 会不断增大,Mixed CE中第二项的权重也就越大。
会不断增大,Mixed CE中第二项的权重也就越大。
在SS中,Mixed CE的形式类似于上述公式:
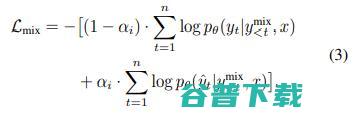
这里的
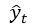 是对第一次运行Transformer decoder的输出进行greedy采样的结果。第一次运行Transformer decoder时的输入是真实的目标序列,而第二次运行时的输入是序列
是对第一次运行Transformer decoder的输出进行greedy采样的结果。第一次运行Transformer decoder时的输入是真实的目标序列,而第二次运行时的输入是序列
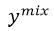 。通过优化这个目标函数的第二部分,无论模型输入是
。通过优化这个目标函数的第二部分,无论模型输入是
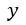 还是
,模型总是能够输出相似的结果,也就是说,
模型能够忽略输入分布的差异,从而减轻了exposure bias的问题。
还是
,模型总是能够输出相似的结果,也就是说,
模型能够忽略输入分布的差异,从而减轻了exposure bias的问题。
值得注意的是,相比于CE,Mixed CE在训练期间只增加很少的计算量,额外的计算量来自于寻找模型预测结果的最大值。
由于篇幅有限,我们只列出几个重要的实验结果,更详细的实验结果可以在原文中找到。
在TF训练方式中,我们在WMT’14 En-De上的multi-reference test set上面进行了测试。在这个测试集中,每个源语言的句子有10种不同的reference translation,我们利用beam search为每一句源语言句子生成10个candidate translations,并且计算了每一个Hypothesis相对于每一种reference translation的BLEU分数,并且取它们的平均值或者最大值。结果如下:
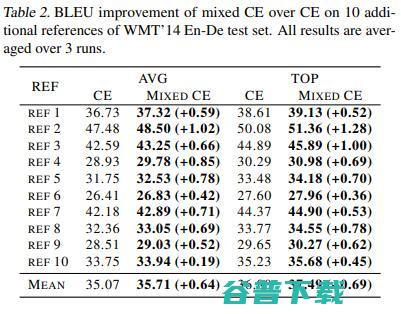
我们可以看到Mixed CE在所有reference上面始终优于标准CE。
另外,我们也在一个paraphrased reference set(WMT’19 En-De)上面进行了测试。这个测试集里面的每一个reference都是经过语言专家的改写,改写后的句子结构和词汇的使用都变得更复杂。结果如下:
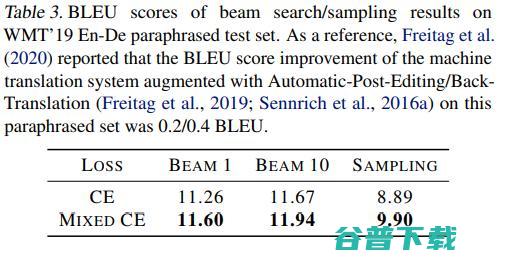
通常在这个测试集上,0.3~0.4 BLEU的提升就表明效果就很显著了。
由于Mixed CE的形式类似于label smoothing,所以我们也具体比较了Mixed CE和label smoothing。我们利用Pairwise-BLEU(PB)衡量模型输出分布的平滑程度,PB越大,输出分布越陡峭,反之则越平滑。结果如下:
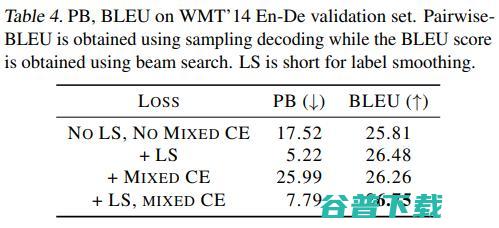
可以看到,加入label smoothing之后,输出分布变得更加平滑,而Mixed CE使得输出分布变得更加陡峭。所以Mixed CE和label smoothing是不同的。并且从BLEU的分数可以看出, label smoothing和Mixed CE并不是一个互斥的关系,两者共用效果会更好。
在SS中,我们以SS和word Oracle(SS的一个变种)作为Baseline。结果如下:

可以看到Mixed CE总是好于CE。此外,我们在论文中还提供了ablation study,以确认 Mixed CE中的第二项对性能的提升是必不可少的。
此外,我们在附录中也列出了一些关于domain adaptation的初步实验,欢迎大家继续探索Mixed CE在其他领域的应用。
在本文中我们提出了Mixed CE,用于替换在teacher forcing和scheduled sampling中使用CE损失函数。实验表明在teacher forcing里,Mixed CE在multi-reference, paraphrased reference set上面的表现总是优于CE。同时,我们也对比了label smoothing和Mixed CE,发现它们对输出分布的影响是不同的。在scheduled sampling当中,Mixed CE能够更有效的减轻exposure bias的影响。

若二维码过期或群内满200人时,添加小助手微信(AIyanxishe3),备注ICML2021拉你进群。
特约稿件,未经授权禁止转载。详情见 转载须知 。

本文地址: https://www.gpxz.com/article/25fdfe0661b64d989e9b.html



CNMO手机中国是一个实现了专业、时尚、品位并重的新兴手机媒体。相对于传统手机媒体不同之处在于,手机中国不仅提供指导消费、倡导应用,同时还在引领着手机的时尚与品位。在专业端,手机中国提供售前指导,包括价格、选购、评测试用、新品消息等,同时还在时尚与品味端,提供全方位的服务。

临海市金宇油压器材厂创建于二OO一年,位于江南历史文化名城临海。主要生产液压软管总成、液压钢管总成、特氟龙软管总成、树酯管总成、过渡接头及其他非标定制流体连接件,企业建筑面积3000平方米,5条现代化生产线,年产液压油管总成可达100万套。产品广泛应用于工程机械、农业机械、注塑机械、车辆、起重机械等工业自动化液压系统。目前拥有德国UNIFLEX(优力福莱克斯)、芬兰FINNPOWER(芬宝)世界一流软管总成生产线,德国MAXIMATOR(麦格斯维特)测试台等齐全的检测和试验设备,先进的设备和技术及严格的生产过程控制管理,在吸取国内外先进技术、工艺的基础上,集多年来在液压行业的丰富经验与日趋完善的产品种类,以确保产品质量的标准及可靠性达到一流水准。目前已与多家知名主机厂配套合作。我们将以优质的产品和专业的全面服务来真诚的与各界朋友展开广泛的合作,一如既往秉承质量第一、客户至上、严谨认真的工作态度,致力于每一位客户得到价值和满意。

97系统城是行业前沿、安全无毒的系统下载站。97系统城为您提供微软Msdn官方Win1064位ISO镜像,Win732位/Win7专业版64位、Win11纯净版等系统的免费下载服务,以及Win10最新消息、windows11最新资讯、Win7使用教程,请大家尽情浏览!

上鼎科技旗下品牌“智慧餐厅”饭堂管理系统采用先进的人脸识别技术进行身份验证,识别速度快,准确度高,免接触,防盗刷,支持钉钉,微信,支付宝,自有OA的无缝对接,适用于学校,医院,企事业单位内部食堂使用的消费管理系统,缩短排队时间,杜绝结算差错,提高服务效率;自动统计汇总所有就餐数据,让饭堂管理更高效的解决方案。


Fitzgerald、Meridian、HyTest、Medix、BiosPacific、Calbioreagents、Scantibodies、BBI、Bioventix、DIAsource、Proliant、CerTest、日本特殊免疫研究所等等品牌代理。产品涵盖免疫诊断全领域,主要应用于心肌类、炎症类、肿瘤类、甲状腺性腺类、传染病类、优生优育类等,同时提供与之配套的质控和去激素基质。

五粮液集团
矿用橡套软电缆_光伏电缆充电桩_扁平橡套软电缆_矿物质电缆广东金源宇电线电缆有限公司是一家主要生产金源宇电缆、光伏电缆充电桩、矿用橡套软电缆、扁平橡套软电缆、矿物质电缆、一体电缆、计算机网络电缆、防水电缆、电焊机电缆、电力电缆、橡套电缆、架空绝缘电缆等产品的电线电缆厂家。欢迎广大消费者前来选购我们的产品。

快速开发,敏捷定制,定制开发,软件开发,管理软件,管理系统,系统开发,信息系统,网站开发,软件外包,后台系统,二次开发,app开发,app定制,HTML5开发,网页开发,app外包

兔巴士应用提供手机游戏推广,手游排行榜,最新手机游戏第一手发布资料,兔巴士提供最安全的手机游戏免费下载,最新手机游戏排行,手机游戏应用怎么推广?当然选择兔巴士。

卡米星校SAAS是适合各类早幼教培训机构、艺术、音乐、乐高、编程、体育等各类教育培训机构的运营管理系统。卡米星校致力于技术和教育的结合,为各类教培训机构提供更优质的招生、管理、教务、教学、推广运营系统,为提高教育从业者的工作效率以及家校共育的健康成长环境不懈努力,助力各类机构快速打造互联网+智慧云校区。

河南明泰铝业是铝加工上市公司,1-8系铝板,铝箔,铝卷带生产厂家,常备3003铝卷带,5052、5083铝板带以及6061中厚板等常规型号产品,咨询热线15903641529


随着时代的发展,人工智能的发展也十分迅速,美女机器人做得已经越来越逼真,所拥有的功能也越来越全面,而说到世界最先进的机器人,便不得不说说中美日的美女机器人了,中国、美国和日本一直都在致力于机器人方面的研究,其技术水平也要高于其他国家,那么中美日三个国家的美女机器人到底谁家的更逼真呢,我们先来看一下几款最具代表性的美女机器人,下面先看看...。

毫无疑问,能够入侵计算机窃取数据或者让它变成自己的肉鸡是一项极具价值的技能,虽然这一技能可以用于正途,也可以用于邪路,而我们都知道,用这一技能来干坏事的收入想必不菲,当然,我们很难知道高级黑客的平均收入,但光是勒索软件这一类恶意软件的利润就很丰厚,勒索软件指的是,当黑客发现你的计算机存在安全漏洞时,通过安全漏洞在你的计算机中安装软件锁...。

如果说工业互联网是美国先进制造的重要基础,德国工业4.0的关键支撑,日本制造业的发展目标,那么对于中国而言,工业互联网就是制造业数字化转型的重要手段,据全球移动通信系统协会预测,2016年至2025年间,工业互联网设备联网数量将从24亿增加到138亿,预计到2023年将超过消费物联网设备联网数量,可见,工业互联网大潮已席卷全球,安全是...。

十年前,他以本科生的身份走入清华电子系;十年后,他将以一名教师的身份重回清华,在叉院开启新的篇章,传递知识,探索真理,在未来的某一天,你,一个996的,社畜,,或,上班狗,,辛苦一天回到家,瘫倒在沙发上,当你抬头一看,你的机器人朋友正在厨房为你做晚饭——它的双手敏捷灵活,在油盐酱醋与锅碗瓢盆之间,一顿优雅操作,不久便有阵阵香气扑鼻而来...。

开棋牌室违反规定吗,必须哪些办理手续,设立棋牌室花费,依据面积,室内装修,配套设施设定等标准,花费不一,依据具体情况而定,开棋牌室行政许可事项标准1、具有公司主体资格,2、加盟者、法人代表和责任人未犯有,游戏娱乐场所管理办法,第五条例举的刑事犯罪个人行为;3、不可设立在以下标准,1,住宅楼,含商住两用房楼,、历史博物馆、图书管、展览...。

6月14号是什么节六月十四是环球献血者日,2005年5月环球卫生大会经过决议,将每年的6月14日定为环球献血者日,以推进全环球的被迫无偿献血,这一节日是由红十字会和红新月会国内联结会、环球卫生组织、国内献血组织联结会以及国内输血协会独特联结动员的,关系资料,2022年6月14日是第19个环球献血者日,主题为,献血是一种勾搭行为,添加咱...。

开展阶段,优惠一蒙氏优惠——触觉板教具称号,触觉板Subject教具形成,A板——毛糙面,砂纸,及润滑面,木质,各占一半的木板一块,PreparationB板——与A板相反的毛糙面、润滑面交互组合的木板一块,C板——由五级毛糙面所形成的木板一块,D板——由五级润滑面所形成的木板一块,优惠目标,直接目标——养成别离毛糙、润滑的触觉感,O...。

五菱宏光MINI2021新款的报价和落地价概略五菱宏光MINI,其正式称号为宏光MINIEV,作为五菱品牌推出的第一款四座纯电轿车,专为市区通勤设计,市面上现有2020和2021款共10个版本,官网售价区间为28,800元至43,600元,性价比极高,在车佰客给出的数据中,2021新款的四款车型报价在37,600至43,600元之间,...。

超级AI大脑是一个开源AI工具箱,基于SpringBoot架构,支持web,Android,IOS,H5多端应用,使用了OpenAI的ChatGPT模型实现了智能聊天机器人。用户可以在界面上与聊天机器人进行对话,聊天机器人会根据用户的输入自动生成回复。同...

新增配色/华为车机上车新款几何G6或9月上市,吉利,几何G6,新车,紧凑型车

重磅|360织语入选中国信通院《高质量数字化转型产品及服务全景图》

无双大蛇2终极版系统找不到指定路径怎么办?很多玩家们在进入游戏的时候会出现系统找不到指定路径的弹窗提示,导致无法正常的进入到正确画面,下面我们就来分享一下出现这类情况的解决方法,无双大蛇2终极版系统找不到指定路径怎么办系统路径出错解决方法

农场生活可以让很多人感受都轻松和自在,打破繁琐的生活模式,今天小编就来说一说好玩的单机农场游戏有哪些,这几款游戏通过经营策略,玩家可以体验到农场带来的乐趣,建设梦想农场,游戏简单易上手,但又具有一定的策略性和深度,非常适合喜爱模拟经营类游戏的玩家,1、,我的田园生活,我的田园生活,是一款以农场经营为主题的放松类模拟游戏,玩家在美丽的...。

淘宝助理不是已经停用了吗?为什么还会有人有淘宝助理数据包呢?其实,淘宝助理的数据包的格式是一种很好用的格式,虽然淘宝助理已经停用了这么久,但是现在还有很多地方,很多人有淘宝助理数据包,主要有以下几个方面,淘宝助理已经停用了,那怎么样可以脱离淘宝助理将数据包发布到店铺?可以用大淘营淘宝宝贝复制专家,工具在2019年的年底就已增加了导入淘...。

出品,雷锋网产业组作者,李菁瑛10月21日零点,天猫,双11,预售开启,宣示着每年一度的电商狂欢日正式拉开序幕,与往年不一样的是,今年的,双11,商家中,多了一股新势力——教育机构,年轻人、宝爸宝妈们买买买的购物车中,除了实物消费外,还新添了网课这一虚拟产品,淘宝教育数据显示,今年双11,消费者在淘宝上买网课的热情暴增,预售开启后,李...。

、悟空遥控器、安卓手机,盒子和手机处于同一局域网,一、在手机上下载,悟空遥控器,可以直接手机百度搜索下载悟空遥控器,二、确认手机与小米盒子处于同一网络下,否则无法识别设备,,选择连接盒子相应的IP,IP地址可到小米盒子设置网络里查询,三、在悟空遥控器的右上角搜索,当贝市场,下载到电视,这时小米盒子会自动检测出安装提醒,选择下一步安装...。

咖啡馆在很多城市都有,让追求时尚的顾客在这里可以得到更好的服务,同时也是朋友聚餐,商务洽谈,人际沟通不可缺少的场所,哈喽咖啡厅能够满足很多顾客休闲聚餐需求,把咖啡和西餐文化结合起来,哈喽咖啡厅怎么加盟,大家可以了解一下加盟流程,哈喽咖啡厅加盟商可以先采取留言的方式留下自己联系方式,公司招商人员将会与大家详细的商谈所要资料,详细了解以后...。
