显著降低模型训练成本的主动增量学习 CVPR 2017精彩论文解读 (显著降低模型的方法)
雷锋网 AI 科技评论按:计算机视觉盛会 CVPR 2017已经结束了,雷锋网 AI 科技评论带来的多篇大会现场演讲及收录论文的报道相信也让读者们对今年的 CVPR 有了一些直观的感受。
相对于 CVPR 2017收录的共783篇论文,即便雷锋网 AI 科技评论近期挑选报道的获奖论文、业界大公司论文等等是具有一定特色和代表性的,也仍然只是沧海一粟,其余的收录论文中仍有很大的价值等待我们去挖掘,生物医学图像、3D视觉、运动追踪、场景理解、视频分析等方面都有许多新颖的研究成果。
所以我们继续邀请了宜远智能的刘凯博士对生物医学图像方面的多篇论文进行解读,延续之前最佳论文直播讲解活动,陆续为大家解读2篇的论文。
刘凯博士是宜远智能的总裁兼联合创始人,有着香港浸会大学的博士学位,曾任联想(香港)主管研究员、腾讯高级工程师。半个月前宜远智能的团队刚刚在阿里举办的天池 AI 医疗大赛上从全球2887支参赛队伍中脱颖而出取得了第二名的优异成绩。
在 8 月 1 日的直播分享中,刘凯博士为大家解读了「Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally」(用于生物医学图像分析的精细调节卷积神经网络:主动的,增量的)这篇论文,它主要解决了一个深度学习中的重要问题:如何使用尽可能少的标注数据来训练一个效果有潜力的分类器。以下为当天分享的内容总结。

刘凯博士:大家好,我是深圳市宜远智能科技有限公司的首席科学家刘凯。今天我给大家介绍一下 CVPR 2017 关于医学图像处理的一篇比较有意思的文章,用的是 active learning 和 incremental learning 的方法。
今天分享的主要内容是,首先介绍一下这篇文章的 motivation,就是他为什么要做这个工作;然后介绍一下他是怎么去做的,以及在两种数据集上的应用;最后做一下简单的总结,说一下它的特点以及还有哪些需要改进的地方。

其实在机器学习,特别是深度学习方面,有一个很重要的前提是需要有足够量的标注数据。但是这种标注数据一般是需要人工去标注,有时候标注的成本还是挺高的,特别是在医学图像处理上面。因为医学图像处理需要一些 domain knowledge,就是说医生对这些病比较熟悉他才能标,我们一般人是很难标的。不像在自然图像上面,比如ImageNet上面的图片,就是一些人脸、场景还有实物,我们每个人都可以去标,这种成本低一点。医学图像的成本就会比较高,比如我右边举的例子,医学图像常见的两种方式就是X光和CT。X光其实一个人一般拍出来一张,标注成本大概在20到30块钱人民币一张;CT是横断面,拍完一个人大概有几百张图片,标注完的成本就会高一点,标注的时间也会比较长。
举个例子,比如标1000张,这个数据对 deep learning 来说数据量不算太大,X光需要2到3万人民币、3到4天才能标完;CT成本就会更长,而且时间成本也是一个很重要的问题。那要怎么解决深度学习在医学方面、特别是医学图像方面的这个难题呢?就要用尽量少的标注数据去训练一个 promising 的分类器,就是说一个比较好的分类器。
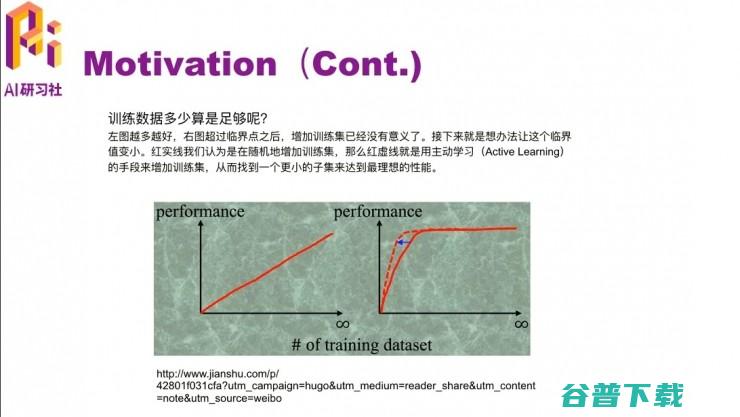
那我们就要考虑要多少训练数据才够训练一个 promising 的分类器呢?这里有个例子,比如左边这个图,这个模型的 performance 随着数据的增加是一个线性增长的过程,就是说数据越多,它的 performance 就越高。但在实际中,这种情况很少出现,一般情况下都是数据量达到一定程度,它的 performance就会达到一个瓶颈,就不会随着训练数据的增加而增加了。但是我们有时候想的是把这个临界点提前一点,让它发生在更小数据量的时候。比如右边这个图的红色虚线部分,用更小的数据达到了相同的 performance。这篇论文里就是介绍主动学习 active learning 的手段,找到一个小数据集达到大数据集一样的效果。

怎么样通过 active learning 的方式降低刚才右图里的临界点呢?就是要主动学习那些比较难的、容易分错的、信息量大的样本,然后把这样的样本标记起来。因为这些是比较难分的,容易分的可能几个样本就训练出来了,难分的就需要大量的数据,模型才能学出来。所以模型要先去学这些难的。
怎么去定义这个“难”呢?就是 “难的”、“容易分错”、“信息量大” ,其实说的是一个意思。这个“信息量大”用两个指标去衡量,entropy大和diversity高。entropy就是信息学中的“熵”,diversity就是多样性。这个数据里的多样性就代表了模型学出来的东西具有比较高的泛化能力。举个例子, 对于二分类问题,如果预测值是在0.5附近,就说明entropy比较高 ,因为模型比较难分出来它是哪一类的,所以给了它一个0.5的概率。
用 active learning 去找那些比较难的样本去学习有这5个步骤
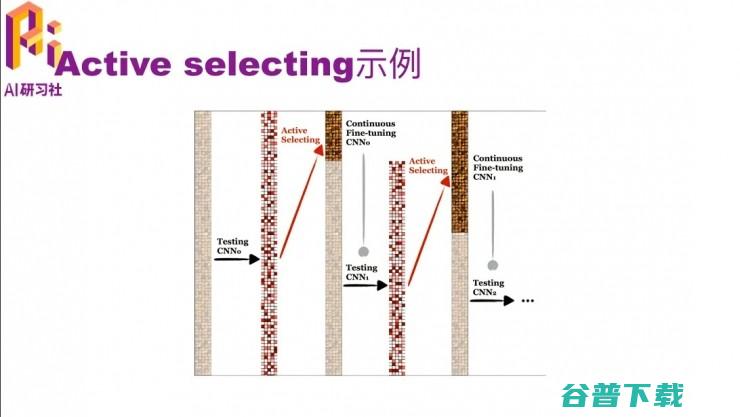
刚才的文字讲解可能不是很直观,我们用一个图来看一下。这个图从左到右看,一开始灰蒙蒙的意思是都还没有标注,然后用一个pre-trained model去预测一遍都是哪个类。这样每个数据上都有一个概率,可以根据这个概率去选择它是不是难分的那个数据,就得到了中间这个图,上面那一段是比较难的,然后我们把它标注出来。然后用一个 continuous fine-tune 的 CNN,就是在原来的模型上再做一次 fine-tune,因为有了一些标注数据了嘛,就可以继续 fine-tune了。fine-tune后的模型对未标注的数据又有了一个预测的值,再根据这些预测值与找哪些是难标的,把它们标上。然后把这些标注的数据和之前就标注好的数据一起,再做一次continuous fine-tune,就得到 CNN2了。然后依次类推,直到把所有的数据都标完了,或者是在没有标完的时候模型的效果就已经很好了,因为把其中难的数据都已经标完了。

刚才提到了两个指标来判定一个数据是不是难分的数据。entropy比较直观,预测结果在0.5左右就认为它是比较难分的;但diversity这个值不是很好刻画,就通过>

这就会产生一个问题,原始的图像,比如左边这只小猫,经过平移、旋转、缩放等一些操作以后得到9张图,每张图都是它的变形。然后我们用CNN对这9张图求是一只猫的概率,可以看到上面三个图的概率比较低,就是判断不出来是一只猫,我们直观的去看,像老鼠、狗、兔子都有可能。本来这是一个简单的例子,很容易识别出来这是一只猫,但是增强了以后反而让模型不确定了。这种情况是需要避免的。
所以这种时候做一个 majority selection,就是一个少数服从多数的方式,因为多数都识别出来它是一只猫了。这就是看它的倾向性, 用里面的6个预测值为0.9的数据,上面三个预测值为0.1的就不作为增强后的结果了 。这样网络预测的大方向就是统一的了。

这篇文章的创新点除了active learning之外,它在学习的时候也不是从batch开始,而是sequential learning。它在开始的时候效果就不会特别好,因为完全没有标注数据,它是从一个ImageNet数据库训练出的模型直接拿到medical的应用里来预测,效果应该不会太好。然后随着标注数据的增加,active learning的效果就会慢慢体现出来。这里是在每一次fine-tune的时候,都是在当前的模型基础上的进一步fine-tune,而不是都从原始的pre-train的model做fine-tune,这样就对上一次的模型参数有一点记忆性,是连续的学习。这种思路就跟学术上常见的sequntial learning和online learning是类似的。但是有一个缺点就是,fine-tune的参数不太好控制,有一些超参数,比如learning rate还有一些其它的,其实是需要随着模型的变化而变化的,而且比较容易一开始就掉入local minimal,因为一开始的时候标注数据不是很多,模型有可能学到一个不好的结果。那么这就是一个open的问题,可以从好几个方面去解决,不过解决方法这篇文章中并没有提。

这个方法在机器学习方面是比较通用的,就是找那些难分的数据去做sequntial的fine-tune。这篇论文里主要是用在了医学图像上面,用两个例子实验了结果,一个是结肠镜的视频帧分类,看看有没有病变、瘤之类的。结论是只用了5%的样本就达到了最好的效果,因为其实因为是连续的视频帧,通常都是差不多的,前后的帧都是类似的,不需要每一帧都去标注。另一个例子也是类似的,肺栓塞检测,检测+分类的问题,只用1000个样本就可以做到用2200个随机样本一样的效果。

这个作者我也了解一些,他是在 ASU 的PhD学生,然后现在在梅奥,美国一个非常著名的私立医院梅奥医院做实习,就跟需要做标注的医生打交道比较多。这相当于就是一个从现实需求得出来的一个研究课题。
总结下来,这篇文章有几个比较好的亮点。

我今天分享的大概就是这些内容。其实这里还有一个 更详细的解释 ,最好还是把论文读一遍吧,这样才是最详细的。
Q:为什么开始的时候 active learning 没有比random selection好?
A:其实不一定,有时候是没有办法保证谁好。active learning在一开始的时候是没有标注数据的,相当于这时候它不知道哪些数据是hard的,在这个医学数据集上并没有受到过训练。这时候跟 random selection 就一样了,正在迁移原来 ImageNet 图像的学习效果。random selection 则有可能直接选出来 hard的那些结果,所以有可能比刚开始的active selecting要好一点,但这不是每次都是 random selection 好。就是不能保证到底是哪一个更好。
(完)
雷锋网 AI 科技评论整理。系列后续的论文解读分享也会进行总结整理,不过还是最希望大家参与我们的直播并提出问题。
中山大学金牌队伍分享获奖经验:如何玩转图像比赛
原创文章,未经授权禁止转载。详情见 转载须知 。

本文地址: https://www.gpxz.com/article/3dbcf2257fc77c1955dc.html



浙江霍普金森流体控制有限公司

江苏伊仕德包装集团有限公司成立于2021年,是一家集设计、研发、生产工业产品包装容器的企业。公司位于江苏南大门――――昆山市锦溪古镇,占地面积29970平方米,拥有现代化标准厂房1万多平方米,年产包装容器150多万只。集团所属企业包括:上海明浩包装材料有限公司、明浩塑胶科技(昆山)有限公司、昆山骏嘉装饰材料有限公司。

庆云华兴钢架工程有限公司

微世推(UDXD.com)免费B2B网站供应信息发布平台,拥有百万供应厂家产品报价,以及B2B电子商务企业名录工厂展示,企业贸易货源采购首选的网站,为厂商便捷服务,更为公司提供永久免费产品信息发布体验。

易网数据专注行业资讯发布,服务器行业的自动发布信息,友情链接交换收录查询平台!

百洋医药集团是以科技创新为驱动力的健康产业集团。集团以商业化能力为基础,以资产增值为核心,以创新孵化为特色,核心业务包括健康品牌商业化平台和创新成果投资孵化,致力于以科技创新优化医疗场景。

武汉蓝海智控科技有限公司成立于2016年5月,注册资金5000万元。蓝海自成立以来一直专注于先进制造业的智能化工程,结合客户产业特性量身规划并实施符合客户个性化需求的作业系统与生产环境,为客户提供安全、稳定、高效、节能的工厂建设及升级服务。致力于解决制造业工厂智能化过程中遇到的“不好管、投入高、难衔接、难扩展、不安全难运维”等现实技术难题、操作难题以及可持续难题。

河北广特紧固件制造有限公司以研发、生产、销售地铁螺栓、地铁管片螺栓系列紧固件产品为一体的综合型企业,本公司下属各厂技术力量雄厚,以机械为主,以及精湛的手工操作技艺专业生产各种规格地铁管片螺栓系列产品。

天津津通阀门制造有限责任公司

静岡県浜松市にてDC金型の冷却部品開発や樹脂製プレス型の設計・開発を行っています。東海を中心に日本全国サービスを提供しております。極小ロットも対応します。

山东伟杰公司主要生产:煤矿梯子间用玻璃钢外覆材料制品、立井罐道与罐道梁、拉挤型材玻璃钢梯子间、防腐热浸锌聚氨酯粉末涂层复合、聚脲涂层材料、玻璃钢有无机风管、玻璃钢冷却塔、玻璃钢水箱等六大系列数百个规格品种,技术性能和实用性能具佳的优质产品玻璃钢,广泛应用于煤矿、化工、石油、建筑、制冷、防腐以及民用设施中。

高校职聘网(www.zhipin8.com)专注于高校人才的招聘工作,主要涵盖高层次人才招聘,高校教师招聘,高校科研人员招聘,高校博士后招聘,高校辅导员招聘,高校行政人员招聘,事业单位招聘等


小编今天给大家带来的是好玩的竞技类游戏大全的相关介绍,竞技类游戏那可是充满刺激与挑战,让人热血沸腾,在这里为你推荐几款超棒的竞技游戏,无论是团队协作的激烈对抗,还是个人实力的巅峰对决,都能让你沉浸其中,今天小编就给大家带来几款这样游戏的介绍,如果有喜欢的小伙伴就跟着我接着往下看看吧,1、,坦克世界闪击战,游戏特色方面里面坦克超多,近几...。

火遍全球的特斯拉在中国市场遭遇到了前所未有的低谷,从大规模的人员变动到销售成绩大幅度滑坡再到车展闹出撞人新闻,作为新型汽车的开路先锋,特斯拉在几年之内经历了过山车式的变化,就在特斯拉出现前所未有的挑战时,国内互联网企业却一头扎进了汽车行业,此时的新能源汽车和智能汽车仿佛是一座围城,里面的人有苦难言,外面的人心之向往,前车之鉴不可不学,...。

雷锋网梳理了近两个月内,有关财务科技、协同数字化、云视频、电子签名等产业互联网重要赛道的融资事件和变化,众言科技获1.8亿元C,轮融资3月22日,众言科技宣布完成1.8亿元C,轮融资,本轮融资由IDG资本、前海母基金、中青旅红奇基金共同领投,元禾控股跟投,众言科技成立于2008年,旗下子公司包括调研平台,问卷网,及客户体验管理平台,倍...。

作者丨何思思编辑丨林觉民缘何命名为澜码,周健这样说,寓意波澜壮阔的代码,独家消息,近日澜码科技宣布完成千万人民币的A轮融资,IDG资本、联新资本、AtomCapital参与了本次投资,澜码科技于今年2月份在上海成立,与其他创业公司不同的是,澜码科技想做的是基于大模型打造新一代的自动化平台,从成立时间上看,其与大模型在国内火的时间...。

发表在专业问答2020,11,920,03展示机型信息,品牌型号,明基w1120、当贝盒子B1、iPhone11系统版本,null、当贝OS2.0、ios14明基W1120不具备智能操作系统,所以无法投屏,需要使用hdmi线连接一个智能电视盒子,当手机与电视盒连接同一局域网后,手机打开无线投屏功能,搜索连接对应的电视盒子即可投屏,明基...。

全球时报,全球网报道记者白云怡,在12日的外交部例行记者会上,有媒体提问称,菲律宾国防部长吉尔伯特·特奥多罗当天示意,中国正对菲律宾施加越来越大的压力,试图让菲律宾丢弃其在南海的主权权益,他还称菲律宾是所谓,中国侵略,的受益者,中方对此有何评论,对此,中国外交部发言人林剑回应示意,针对菲方无关人士的舆论,我要指出的是,每一次性中菲海...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

1.白羊座白羊座性情单纯,看似没有任何神思谋略,其实就是看透了不说透,不想受伤而已,这个星座的性情真的太便捷了,就像一张白纸,没有任何共计和谋略,假设真要陈列一个便捷的名单,那么一切星座都排在第一,白羊座相对可以称得上第一,由于白羊座仿佛对人世万物都有着最原始的认识、想法等等,而且特意天真可恶,然而白羊座并没有大家构想的那么特意单纯,...。

大霸王1.3用的是东安D系列发起机1.5的才是4G15S开售员忽悠你了我是沈阳卖哈飞的面包这玩意其实都差不多你问问周围用车的让他们给介绍团体感觉五菱外型差点哈飞路尊大霸王的发起机能否是前置,是的,咱们是哈飞的哈飞路尊大霸王1.3排量的是什么发起机,会不会是小马拉大车,三菱改的,不会,不过也只是够用罢了,...。

SmartGit是一款图形化的Git客户端,支持GitHub、Bitbucket和GitLab。该客户端软件允许您以最少的努力访问在线存储库、进行更改和推送新的提交。
金山毒霸,金山毒霸是金山公司推出的一款最新高智能反病毒杀毒软件,金山毒霸杀毒软件下载具备全平台、全引擎、全面网购保护并融合了启发式搜索、代码分析、虚拟机查毒等经业界证明成熟可靠的反病毒技术,您可以免费下载。

很多家长为了孩子的学习会花费大量的金钱,孩子教育问题就是家长关注的事情,在中考或者高考等大考的时候,很多家长会为孩子报名各种冲刺的班级,以希望提高孩子的成绩,而选择一个好的教育机构就很重要,其中考试大师就在众多的品牌脱颖而出,很多网友就看中该商机,并想要加入其中,那么,考试大师能加盟吗,门槛高不高,考试大师是一个全新的赛道,拥有蓝海的...。

12月4日,在广西三江富禄苗族乡仁里小学的校园里,一堂别开生面的宪法知识课正在进行,来自珠海边检总站开平边检站驻村支教移民管理警察罗洪伟为孩子们带来一场生动、有意义的宪法知识启蒙,课堂上,移民管理警察身着威严的警服,话语却温和亲切,他用通俗易懂的语言和形象生动的案例,向孩子们讲解宪法是什么,宪法与日常生活有着怎样千丝万缕的联系,从公民...。

北京时间3月11日,第十三届全国人大五次会议正式闭幕,从3月4日政协会议开始,到人大会议闭幕,7天时间里,来自社会各界的代表针对不同行业存在的问题都提出了提案和建议,其中,在科技方面,数字安全、工业互联网、智能制造、智慧交通、数字经济等话题成为重点,掘金志通过梳理这些提案和建议,整理了以下看点,红杉中国沈南鹏,制造业,数智化,转型作为...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。
