1v1胜率99.8% AI 腾讯绝悟 技术解读 2100场王者荣耀 (1v1胜率最高的英雄)
围棋被攻克之后,多人在线战术竞技游戏(MOBA)已经成为测试检验前沿人工智能的动作决策和预测能力的重要平台。基于腾讯天美工作室开发的热门 MOBA 类手游《王者荣耀》,腾讯 AI Lab 正努力探索强化学习技术在复杂环境中的应用潜力。本文即是其中的一项成果,研究用深度强化学习来为智能体预测游戏动作的方法,论文已被AAAI-2020接收。
此技术支持了腾讯此前推出的策略协作型 AI 「绝悟」1v1版本,该版本曾在今年8月上海举办的国际数码互动娱乐展览会China Joy首次亮相,在2100多场和顶级业余玩家体验测试中胜率达到99.8%。
除了研究,腾讯AI Lab与王者荣耀还将联合推出“开悟”AI+游戏开放平台,打造产学研生态。王者荣耀会开放游戏数据、游戏核心集群(Game Core)和工具,腾讯AI Lab会开放强化学习、模仿学习的计算平台和算力,邀请高校与研究机构共同推进相关AI研究,并通过平台定期测评,让“开悟”成为展示多智能体决策研究实力的平台。目前“开悟”平台已启动高校内测,预计在2020年5月全面开放高校测试,并且在测试环境上,支持1v1,5v5等多种模式;2020年12月,我们计划举办第一届的AI在王者荣耀应用的水平测试。
以下是本次入选论文的详细解读:

在竞争环境中学习具备复杂动作决策能力的智能体这一任务上,深度强化学习(DRL)已经得到了广泛的应用。在竞争环境中,很多已有的 DRL 研究都采用了两智能体游戏作为测试平台,即一个智能体对抗另一个智能体(1v1)。
其中 Atari 游戏和棋盘游戏已经得到了广泛的研究,比如 2015 年 Mnih et al. 使用深度 Q 网络训练了一个在 Atari 游戏上媲美人类水平的智能体;2016 年 Silver et al. 通过将监督学习与自博弈整合进训练流程中而将智能体的围棋棋力提升到了足以击败职业棋手的水平;2017 年 Silver et al. 又更进一步将更通用的 DRL 方法应用到了国际象棋和日本将棋上。
本文研究的是一种复杂度更高一筹的MOBA 1v1 游戏。即时战略游戏(RTS)被视为 AI 研究的一个重大挑战。而MOBA 1v1 游戏就是一种需要高度复杂的动作决策的 RTS 游戏。相比于棋盘游戏和 Atari 系列等 1v1 游戏,MOBA 的游戏环境要复杂得多,AI的动作预测与决策难度也因此显著提升。以 MOBA 手游《王者荣耀》中的 1v1 游戏为例,其状态和所涉动作的数量级分别可达 10^600和 10^18000,而围棋中相应的数字则为 10^170和 10^360,参见下表 1。

表 1:围棋与 MOBA 1v1 游戏的比较
此外,MOBA 1v1 的游戏机制也很复杂。要在游戏中获胜,智能体必须在部分可观察的环境中学会规划、攻击、防御、控制技能组合以及诱导和欺骗对手。除了玩家与对手的智能体,游戏中还有其它很多游戏单位,比如小兵和炮塔。这会给目标选择带来困难,因为这需要精细的决策序列和相应的动作执行。
此外,MOBA 游戏中不同英雄的玩法也不一样,因此就需要一个稳健而统一的建模方式。还有一点也很重要:MOBA 1v1游戏缺乏高质量人类游戏数据以便进行监督学习,因为玩家在玩 1v1 模式时通常只是为了练习英雄,而主流 MOBA 游戏的正式比赛通常都采用 5v5 模式。
需要强调,本论文关注的是 MOBA 1v1 游戏而非MOBA 5v5 游戏,因为后者更注重所有智能体的团队合作策略而不是单个智能体的动作决策。考虑到这一点,MOBA 1v1游戏更适合用来研究游戏中的复杂动作决策问题。
为了解决这些难题,本文设计了一种深度强化学习框架,并探索了一些算法层面的创新,对 MOBA 1v1 游戏这样的多智能体竞争环境进行了大规模的高效探索。文中设计的神经网络架构包含了对多模态输入的编码、对动作中相关性的解耦、探索剪枝机制以及攻击注意机制,以考虑 MOBA 1v1 游戏中游戏情况的不断变化。
为了全面评估训练得到的 AI 智能体的能力上限和策略稳健性,新设计的方法与职业玩家、顶级业务玩家以及其它在 MOBA 1v1 游戏上的先进方法进行了比较。
本文有以下贡献:
对需要高度复杂的动作决策的 MOBA 1v1 游戏 AI 智能体的构建进行了全面而系统的研究。在系统设计方面,本文提出了一种深度强化学习框架,能提供可扩展的和异步策略的训练。在算法设计方面,本文开发了一种用于建模 MOBA 动作决策的 actor-critic 神经网络。网络的优化使用了一种多标签近端策略优化(PPO)目标,并提出了对动作依赖关系的解耦方法、用于目标选取的注意机制、用于高效探索的动作掩码、用于学习技能组合 LSTM 以及一个用于确保训练收敛的改进版 PPO——dual-clip PPO。
在《王者荣耀》1v1 模式上的大量实验表明,训练得到的 AI 智能体能在多种不同类型的英雄上击败顶级职业玩家。
考虑到复杂智能体的动作决策问题可能引入高方差的随机梯度,所以有必要采用较大的批大小以加快训练速度。因此,本文设计了一种高可扩展低耦合的系统架构来构建数据并行化。具体来说,这个架构包含四个模块:强化学习学习器(RL Learner)、人工智能服务器(AI Server)、分发模块(Dispatch Module)和记忆池(Memory Pool)。如图 1 所示。
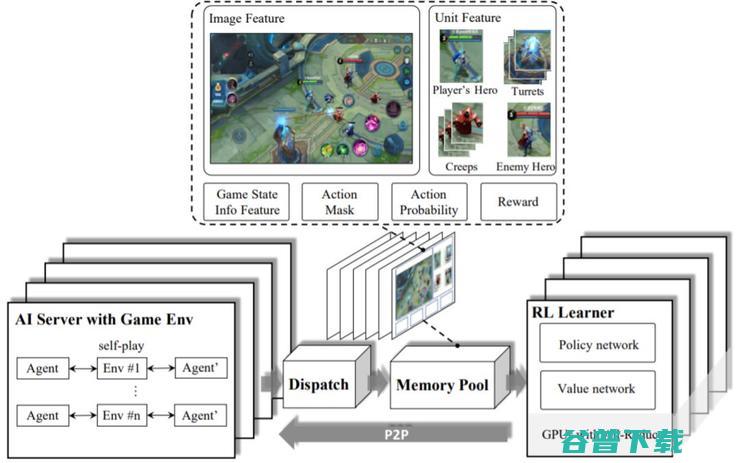
图 1:系统设计概况
AI 服务器实现的是 AI 模型与环境的交互方式。分发模块是用于样本收集、压缩和传输的工作站。记忆池是数据存储模块,能为RL 学习器提供训练实例。这些模块是分离的,可灵活配置,从而让研究者可将重心放在算法设计和环境逻辑上。这样的系统设计也可用于其它的多智能体竞争问题。
RL 学习器中实现了一个 actor-critic 神经网络,其目标是建模 MOBA 1v1 游戏中的动作依赖关系。如图2所示。
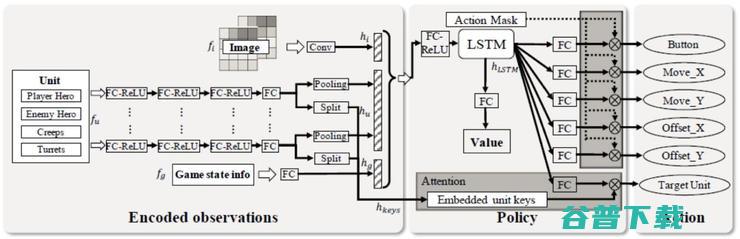
图 2:论文实现的actor-critic网络
为了实现有效且高效的训练,本文提出了一系列创新的算法策略:
1.目标注意力机制:用于帮助AI在 MOBA 战斗中选择目标。
2.LSTM:为了学习英雄的技能释放组合,以便AI在序列决策中,快速输出大量伤害。
3.动作依赖关系的解耦:用于构建多标签近端策略优化(PPO)目标。
4.动作掩码:这是一种基于游戏知识的剪枝方法,为了引导强化学习过程中的探索而开发。
5.dual-clip PPO:这是 PPO 算法的一种改进版本,使用它是为了确保使用大和有偏差的数据批进行训练时的收敛性。如图3所示。

图 3:论文提出的dual-clip PPO算法示意图,左为标准PPO,右为dual-clip PPO
有关这些算法的更多详情与数学描述请参阅原论文。
系统设置
测试平台为热门 MOBA 游戏《王者荣耀》的 1v1 游戏模式。为了评估 AI 在现实世界中的表现,这个 AI 模型与《王者荣耀》职业选手和顶级业余人类玩家打了大量比赛。实验中 AI 模型的动作预测时间间隔为 133 ms,这大约是业余高手玩家的反应时间。另外,论文方法还与已有研究中的基准方法进行了比较,其中包括游戏内置的决策树方法以及其它研究中的 MTCS 及其变体方法。实验还使用Elo分数对不同版本的模型进行了比较。
实验结果
探索动作决策能力的上限
表 3 给出了AI和多名顶级职业选手的比赛结果。需要指出这些职业玩家玩的都是他们擅长的英雄。可以看到 AI 能在多种不同类型的英雄上击败职业选手。
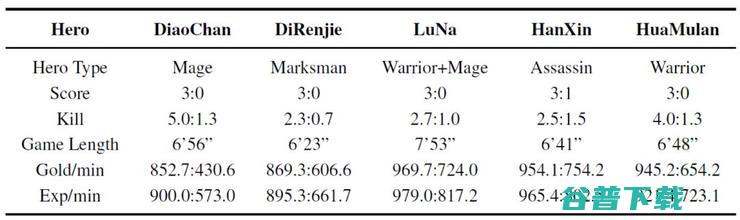
表 3:AI 与职业选手使用不同类型英雄比赛的结果
评估动作决策能力的稳健性
实验进一步评估了 AI 学习的策略能否应对不同的顶级人类玩家。在2019年8月份,王者荣耀1v1 AI对公众亮相,与大量顶级业余玩家进行了2100场对战。AI胜率达到99.81%。
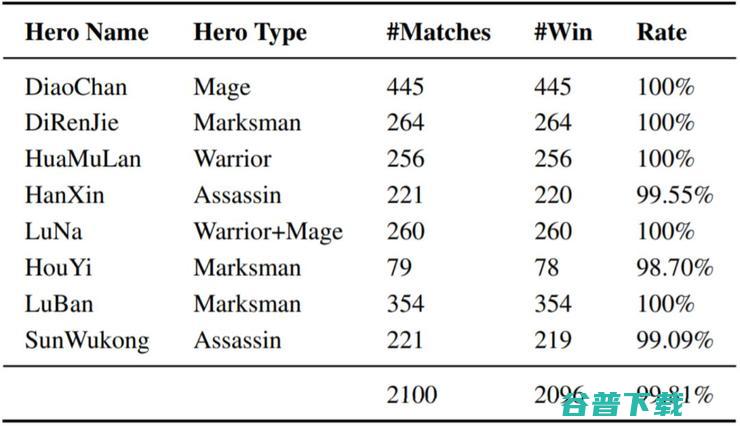
表 4:AI 与不同顶级人类玩家的比赛结果
基准比较
可以看到,用论文新方法训练的 AI 的表现显著优于多种baseline方法。
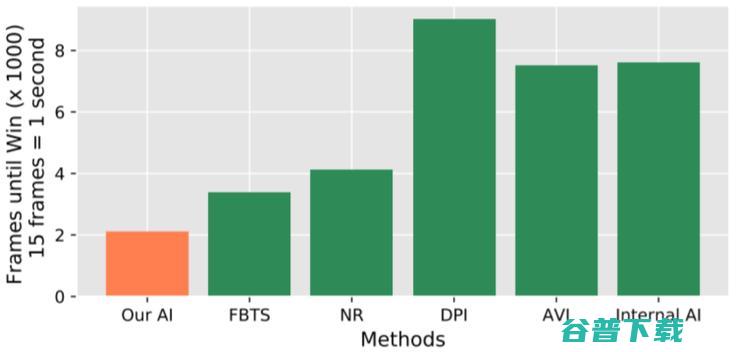
图 4:击败同一基准对手的平均时长比较
训练过程中模型能力的进展
图 5 展示了训练过程中 Elo 分数的变化情况,这里给出的是使用射手英雄「狄仁杰」的例子。可以观察到 Elo 分数会随训练时长而增长,并在大约 80小时后达到相对稳定的水平。此外,Elo 的增长率与训练时间成反比。

图 5:训练过程中 Elo 分数的变化情况
控制变量研究
为了理解论文方法中不同组件和设置的效果,控制变量实验是必不可少的。表 5 展示了使用同样训练资源的不同「狄仁杰」AI 版本的实验结果。
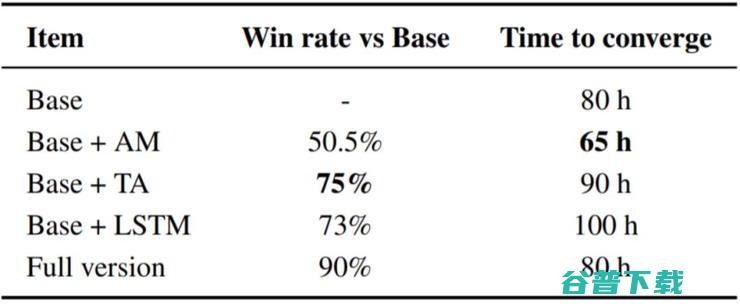
表 5:控制变量实验
4、未来工作
本文提出的框架和算法将在未来开源,而且为了促进对复杂游戏的进一步研究,腾讯也将在未来把《王者荣耀》的游戏内核提供给社区使用,并且还会通过虚拟云的形式向社区提供计算资源。
雷锋网 AI 科技评论报道。
原创文章,未经授权禁止转载。详情见 转载须知 。

本文地址: https://www.gpxz.com/article/65a9124f7f105ad59e9e.html



头条新闻,头条,今日新闻头条,头条网,头条新闻,今日头条新闻

北京大学肿瘤医院(北京肿瘤医院、北京大学临床肿瘤学院、北京市肿瘤防治研究所)始建于1976年,是一所由北京大学、北京市医院管理中心共管的三级甲等肿瘤专科医院。北京大学肿瘤医院设有34个临床科室,14个医技科室,17个基础研究科室,开放床位776张。全年门诊量66万人次,年收治病人7.8万人次,手术近1.6万例。医院职工近2400人,在编职工中正高级职称124人,副高级职称211人。

网址导航――RC0991.COM是最实用的上网导航网站,是方便网民上网的入口平台,及时收录包括网络电视、电景、音乐、视频、小说、游戏等热门分类的优秀网站,与搜索完美结合,提供最简单便捷的网上导航服务,是数千万网民的上网主页。

江西工作服批发厂家【沃克迪威】,中铁工作服定做直供厂家,订购电话17779191800
")
云试剂(www.yunshiji.cn)_为科研人员提供一站式解决方案。产品包括科研试剂、常规耗材、生物耗材、常备仪器、生物仪器、分析仪器、实验工具、员工防护、工业安全、IKA、梅特勒、磁力搅拌、天平、通用试剂、高纯溶剂、异构烷烃、化学试剂、HPLC级溶剂、氘代试剂、催化剂、实验家具、办公用品、解决方案

碳纤维电地暖选河北暖烨电子科技有限公司,暖烨将继续秉持以能为本的核心价值观和诚信治企的经营理念,坚持走质量效益型,资源节约型,期待与您共创辉煌!

驰兔专注工位器具-北京金盛宏昌货架有限公司主要以批发定制为主,主要服务产品有工具挂板、洞洞板、工具架、工具柜、工具车、工作台、仓储货架,欢迎企业前来订购咨询

儿童抽动症能治好吗?北京天使儿童医院是一家专业治疗抽动症的医院,关于抽动症怎么好,多动症治疗方法,中医能治好抽动症等疑问,可在线咨询。

爱享天下是一家拥有多年办理各类国际婚姻,跨国婚姻,海外婚姻,国际婚恋,跨国婚恋,海外婚恋,涉外婚介,跨国交友,海外交友,跨国交友网,海外交友网,海外婚姻介绍网,海外婚恋平台哪个好,欧美婚姻,涉外婚恋,涉外婚恋网,涉外婚恋服务,涉外征婚,跨境相亲,结婚移民,涉外婚姻,婚姻移民。实名制全球猎婚平台.咨询热线:18302009898位于重庆市荣昌区昌龙大道瑞尔国际大厦518室

茶123提供全面的茶叶知识,茶叶常识,茶叶百科,茶叶文献,茶叶鉴别,茶叶制作等相关信息。

奥的斯电梯,长春奥的斯电梯为您提供长春电梯公司,长春电梯定制,长春电梯施工,长春电梯安装,电梯维修公司,长春电梯,长春电梯定制公司,长春电梯施工公司,长春电梯安装公司,长春电梯维修公司专业诚信,值得信赖.

租号王是一个游戏交易和体验服务平台,为用户提供热门游戏(王者荣耀、和平精英、火影忍者、穿越火线、英雄联盟等)的租号道具体验和角色账号的安全交易服务。


相信很多小伙伴们家里都是有小朋友的吧,下面给大家带来的,预2.4,小孩子玩的智力游戏有哪些2022,这些游戏可以帮助小朋友们锻炼动手能力,大家喜欢的话可以点击下面的链接进行下载体验,那么下面一起来看看究竟有哪些高质量的游戏吧,1、,儿童益智切水果,这是一款儿童切水果游戏,游戏的画面卡通可爱,操作简单流畅,在游戏中将有海量的各种不同的水...。

加盟西餐是比较不错的加盟项目,小编今天要为大家介绍的就是加盟雨花西餐的加盟信息哦,大家想要了解的看看本篇文章吧,时间的关系我们在今天的文章里面就只能为大家简单的介绍一下加盟的优势以及加盟的条件了哦,雨花西餐厅其经营的产品包括意大利菜和法国菜,凭借着不凡的产品和贴心的服务,赢得了广泛好评,是非常值得加盟的好品牌,下面就让学习啦小编为你介...。

术后会有一段时间大便带血,肚子疼是伤口的原因.要过一段时间才会慢慢缓解.术后调养要注意饮食,避免酸性食物多吃点碱性食物,红豆、萝卜、苹果、甘蓝菜、洋葱、豆腐萝卜干、大豆、红萝卜、蕃茄、香蕉、橘子、番瓜、草莓、蛋白、梅干、柠檬、菠菜葡萄、海带等.复查对复发的早期发现特别重要,术后二年建议,三个月复查一次,主要是肝、腹腔、盆腔,可以用B超...。

今日,淘宝取消双12的消息冲上微博热搜,引发热议,据淘宝网商家服务大厅消息,,淘宝双12活动今年取消不再举办,今年12月会举办平台大型活动,淘宝年终好价节,,预计11月底开始招商,据悉,,淘宝年终好价节,的具体活动时间为12月8日至12月12日,共为期5天,与去年,双12,活动时间一致,淘宝和天猫将一同参与活动,从,双12,到,淘宝...。

发表在行业动态2021,3,1519,37在今年2月23日,德州仪器,TI,官方正式任命姜寒先生代替胡煜华担任公司副总裁兼中国区总裁,而作为德州仪器原高管的胡煜华将会卸任离开去一个新的地方迎接新的职业挑战,具体去处在今年3月15日正式公开,胡煜华所加盟的公司正是汇顶科技,在2021年3月15日,汇顶科技正式发布公告称,为了满足公司发展...。

发表在坚果投影仪2020,6,2612,24坚果J7Pro投影仪作为坚果投影的新品,非常的受投影爱好者的关注,毕竟,坚果投影是目前家用智能投影仪市场知名的品牌,它的新产品相信一定有什么特别之处,下面我就用坚果J7Pro和当贝F1C进行一个对比,看看两款产品有什么不同,坚果J7Pro和当贝F1C的参数对比表1.光学参数在光学参数方面,坚...。

如果要开启,天气,的地理位置权限,需要点击进入,设置,选项,点击,隐私,选项,再点击,定位服务,选项,进入页面后,找到,天气,选项,选择,使用应用期间,选项,即可开启苹果手机中,在使用天气应用时的位置权限,...。

我们能为您做点什么——将传统企业与移动互联网企业跨界融合,定制化服务,掀起广告革命为您品牌整体形象从定位,规划,实施系统化服务与价值展实施...。

A型血的人和处女座的人一样,经常被标签化,确实每个血型的人有该血型的性情特点,那么A型血女人的性情是怎样的呢?A型血女人的恋情观和价值观是怎样的呢?小编整顿了精选了片面的相关内容,咱们一同来了解一下A型血的女兽性情吧,一、A型血女人的性情,双重性情A型血的人普通都具备双重性情,一方面心思细密,竭力压制自己,不损伤他人,踊跃为他人服务,...。

suv四边形车标是观致,代表着观致品牌的翻新精气和踊跃向上的态度,代表着观致汽车的品牌愿景,观致汽车旗下共有三个车型,包含观致3、观致3都市SUV车型,观致35门版车型,观致汽车作为一家全新的汽车制作公司,消费汽车的平台与国内顶级供应商协作开发,使汽车的机械需要齐全合乎欧洲汽车市场的规范和需求,在汽车一切零部件的供应商中,95%都是来...。

编辑丨艾恬6月21日,中央纪委国度监委网站颁布信息,中央宣传部副部长张建春涉嫌重大违纪违法,目前正接受中央纪委国度监委纪律审查和监察考查,张建春,男,汉族,1965年5月出世,山东郓城人2020年,张建春出任中央宣传部副部长,...。

阿里云创立于2009年,是中国最大的云计算平台,服务范围覆盖全球200多个国家和地区。阿里云致力于为企业、政府等组织机构,提供最安全、可靠的计算和数据处理能力,让计算成为普惠科技和公共服务,为万物互联的DT世界,提供源源不断的新能源。官网:https://www.aliyun.com
win11激活工具_2026年最新Win11永久激活工具下载分享

最近,中视频伙伴计划又更新了一些审核机制,所以有粉丝问我,作为一个互联网新手,如何通过中视频赚钱?我跟他说,其实很多新手小伙伴初入中视频赛道,必然会遇到很多问题,在这些问题中,最重要的不是一万七的播放量,而是要让彻底了解平台的规则,以及性格喜好,行为习惯等,如果你做中视频比较久,就会遇到很多问题,比如有些视频被查重是因为内容搬运,没有...。

雷锋网消息,根据digitimes援引供应链的消息,台积电将会赢得苹果下代A13处理器的全部订单,这将有利于台积电扩大其在晶圆代工领域的市场地位,但对苹果而言,即便采用最先进的7nmEUV工艺,提升A13处理器的性能依旧面临挑战,据悉,台积电2018年上半年在全球晶圆代工市场的份额为56%,如果台积电能获得苹果A13处理器的全部订单,...。

说到最近热播的电视剧,首当其冲的当然要属由杨幂、黄子韬挑大梁的都市情感剧,谈判官,这部剧自开播以来收视率就一路独占鳌头,凭借黄子韬扮演的,落难富二代,谢晓飞与杨幂饰演的高级谈判官童薇之间鬼马可爱又相互扶持成长的姐弟恋情,让观众们饱尝,甜如初恋,虐到心碎,的,快感,当然除了两位男女主角,剧中郭品超扮演的暖男律师秦天宇也颇受关注,这位...。

发表在专业问答2020,3,3015,48展示机型信息,品牌型号,当贝F1系统版本,当贝OS2.0使用投影仪内自带的文件管理器工具进行打开U盘文件,在投影仪的全部应用中找到文件管理器打开即可;使用第三方文件管理器工具进行打开U盘文件,第三方文件管理器需要事先安装,投影仪打开U盘文件,投影仪在机身背后都会有USB接口的设计,将U盘接入投...。
