是时候放弃循环神经网络了! (是时候放弃了)
有人说,不同语言之间的翻译,与其说是一门科学,不如说是一门艺术。
NLP 领域的机器学习工程师 RicCardo Di Sipio 日前提出了一个观点:使用卷积网络要比使用循环神经网络来做 NLP 研究,要幸福得多——是时候放弃循环神经网络了!
基于这一观点,他从卷积网络本身的基本原理出发,论述了为什么 NLP 不再需要循环神经网络的原因。
我们来看:
不久前,人工智能科学家侯世达(Douglas Hofstadter) 就在The Atlantic上发表的一篇论文中指出,目前机器翻译尚处于「浅薄」的阶段。
尽管机器翻译存在局限性,但难以否认的是,自动翻译软件在许多情况下都有良好的效果,而其背后的技术在任何存在信息从一个领域流动到另一个领域的语境中都具有广泛的应用,例如基因组学中从RNA到蛋白质编码的翻译过程。
直到2015年,序列到序列的映射(或者说翻译)使用的主要方法都是循环神经网络,特别是长短期记忆(LSTM)网络。
我在前一篇文章中介绍了这些网络架构的基础知识,我还谈到了LSTM 被应用于大型强子对撞机的顶部夸克对衰变的运动学重建过程。这篇文章链接如下:
然后,出现了一些新的方法:比如残差网路架构和注意力机制的提出,为针对这类任务的更通用的框架的实现铺平了道路。
值得一提的是,这些新颖的网路架构还解决了另一个问题:事实上,由于RNN 固有的时序性,很难利用这种网络在像 GPU 这样的并行系统上进行训练。而这一点正是卷积神经网络使用起来非常方便的地方。
在数学中,卷积表示的是当函数 f 作用于另一个函数 g 时生成第三个函数的一种运算:
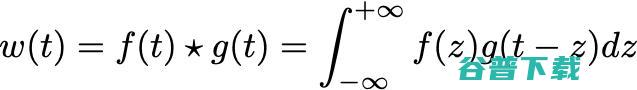
不应与调制(例如AM传输中的EM信号)混淆,调制是将两个函数简单相乘。 求知欲强的人可能会深究到:时间空间中的卷积傅里叶变换,实质上是频率空间中的调制

所以这两种运算虽然密切相关,但切不可被混淆。
在计算机科学的离散世界中,积分被求和取代,两函数之间的乘法由矩阵间的乘法代替。用行话来说,就是将卷积核应用到图像上来生成卷积特征,一次卷积将生成一个新的特征。在下面每一对图像中,当对左边部分发生一次卷积变换,将于右边部分产生一个新的值,如下图所示:

在对这个序列的操作中,图像(灰色矩阵)由一个卷积核(橙色矩阵)卷积操作以获得卷积特征(绿色矩阵)。
通常来说,卷积核是一个网络的权值矩阵,必须通过某种算法(如:反向传播)计算,才能得到它的期望输出。
这种操作的一个很好并且非常重要的特性是,一旦「图片」被加载到记忆中,不同的卷积核会对其进行操作,这样就可以减少输入/输出(I/O)次数,从而更好地利用带宽。通常,卷积操作由以下两种方式执行:
在卷积之后,通常会进行池化操作:在每个卷积块中,只将最大值传递到下一层。此操作用于降低图片维数以及过滤噪声。降维的关键是通过信息压缩来寻找更高水平的特征。
常用的做法是,通过将上述两个步骤的板块链合在一起,来构建一个卷积神经网络。一些成功的网络架构案例如下:
既然现在我们已经了解了卷积神经网络的基本知识,那么让我们回到最原始的问题:我们如何使用这样的网络代替循环网络来解析序列呢?
注意力机制背后的主要观点是,网络应该找出输入序列的哪些部分或元素与生给定的输出序列元素具有更强的相关性。它通过为每个输入元素创建一个注意力权重向量(权重介于0和1之间,通过Softmax产生),并使用它们来调整信息流。如果我们首先关注基于RNN的网络,这将变得更容易理解。
对于每个输入元素(时间阶),RNN层会存储一个隐藏状态。所以对于N个输入将会有N个隐藏状态。此时,我们可以通过简单地让注意力权重和隐藏状态逐个元素相乘(也就是哈达玛积)。来生成剩下文向量:

例如,当翻译一个句子时,两种语言的专有名词都是一样的,因此相应的权重会非常大(例如0.95)。相邻单词的权重很可能也是比较大的(例如0.55),而相距较远的单词权重则较小(例如0.05)。
最后,信息被压缩成一个注意力向量,并传递到下一层:

在解码阶段,则回为每个输入的词计算上下文向量。
现在我们基本掌握和理解了关于如何在机器翻译中摆脱RNN网络的所有要素。
Transformer网络利用注意力机制,但这次使用的是前馈网络。
首先,输入序列被嵌入(即被编码成N维空间中的一个数字)向量作为补充,该向量跟踪每个单词相对于彼此的初始位置。现在我们有了序列中所有单词(K)和一个给定单词(Q)的向量表示。
根据这些材料,我们可以像以前那样计算出注意力权重(代表了维度,它是一个标准化因子):

这个注意力权重决定了其他每个单词对于给定单词的翻译结果的贡献程度。
将这些权重作用于待翻译的给定序列(值V)的过程称为缩放的点积注意力(Scaled Dot-Product Attention)。
多头注意力是一种注意力机制的合并方式,被用来将Q、K和V 线性映射到不同维度的空间中。其思想是,不同的映射可以分别从不同方面突出信息编码的方式。其中映射是通过将Q、K和V乘以训练过程中学习到的矩阵W来实现的。
最后值得一提的损失,在论文《Attention Augmented Convolutional Networks》中,作者提出了一种具有多头注意力机制的CNN,该论文链接如下:
而以上,便是为什么我们不再需要循环神经网络的原因~
via:雷锋网AI 科技评论编译。
原创文章,未经授权禁止转载。详情见 转载须知 。

本文地址: https://www.gpxz.com/article/702737ab97624459cac9.html



证券网站排名,根据网站的综合值按照不同的证券网站进行筛选排名结果,通过筛选证券网站可以看到每个证券网站里面的网站排名优质的网站是哪些

123手机导航--新一代手机安全上网导航。

43号小铺

江苏亿诺热能科技有限公司为您提供轧钢加热炉,天然气加热炉,蓄热式加热炉,步进式加热炉,锻造加热炉,天然气锻造加热炉,天然气热处理炉,天然气退火炉,推钢式加热炉等,拥有多项实用新型和发明专利技术.

苏州市徽仁机电有限公司前身是苏州广兴精密模具厂,地处苏州相城区黄埭工业园。主要致力于精密注塑成型,精密模具设计与制造,精密模具零件加工。

PDF|免费|资料下载|电子书下载|课本,题库,答案,易书读书,让读书更容易,FreePDFDownload|Textbook|Testbank|SolutionManual|Book|交流分享平台。

深圳市一代国际货运代理有限公司

吕梁人才网站助力于为山西地区的求职者提供全面的信息与服务。无论您是寻找教师|护士|司机还是普工的岗位,亦或是希望通过兼职提升个人技能,吕梁人才网都能为您提供最新的招聘信息。吕梁人才网连接学院招聘与事业单位,助力每位求职者顺利找到合适的工作,满足各类人才市场的需求。欢迎来访,探索更多机会!

变压器厂,变压器厂家,变压器生产厂家-光大变压器制造有限公司(13336258888)专业生产各种型号:干式变压器,油浸式变压器,高过载变压器,矿用变压器,非晶合金变压器等,产品涵盖S9,S11,S13,SCB10,SCB11,SCB13,50,80,100,125,160,200,250,315,400,500,630,800,1000,1250,1600KVA

苏州富杰德智能机械设备有限公司专业从事各类船用轴系、舵系、管系(各种阀门、接头及其附件)产品研制和生产的专业厂家。公司主要提供各类瓦锡兰船舶配件,苏尔寿船舶配件,曼恩船舶配件,依托长三角丰富的工厂资源及发达的物流的系统,深度整合行业资源,缩短行业供应链,提升行业效率、释放生产力。

深圳鲸禧工业设计公司是深圳知名的产品设计与制造企业,专业提供产品外观设计,产品结构设计,医疗产品设计,医疗器械设计,医疗设备设计,三防产品设计,消费电子设计,机械设备设计,家电设计,储能电源设计等产品设计及生产供应链管理的综合服务供应商;荣获国家级高新技术企业,深圳市十大工业设计服务机构。

杏仁医药科技重庆有限公司致力于以“线上+线下”模式,以产业互联网、AI数智、区块链、物联网等科技手段,整合上游供应链,为诊所、药房、社区卫生服务中心、村卫生室等全国百万家基层医疗单位提供中药饮片及成药药事服务。


很多的玩家喜欢融入了我国古代文化的,不管是可以算数的游戏还是与汉字有关的,都可以让玩家感受寓教于乐,那么必玩的汉字游戏闯关都有什么呢,接下来盘点几款与汉字有关的闯关游戏,不仅有丰富的关卡需要玩家了解,我国的汉字,更是可以帮助我们家认识诸多汉字的,如果玩家对于汉字闯关游戏比较感兴趣,汉字状元也是能满足需求的,在这款游戏中以汉字为主要的玩...。

以上就是绿色先锋小编整理的goodnotes怎样导入pdf文件的内容了,希望可以帮助到大家!我们会持续为您更新精彩资讯,欢迎持续关注我们哦!...。
要闻提示1.苹果中国官网降价上热搜,新年首周在华销量下降30%2.中国生物制药回应科兴新冠疫苗停产,还有4亿存货,已获分红近60亿3.阿维塔售后大规模裁员,比例高达95%,员工称内部四分五裂,最新回应4.全系车型降价超3万元,理想汽车回应,提前开始产品更新过渡5.美航管局鼓励聘用智力和精神残疾人士,马斯克惊呼难以置信6.苹果造车被曝新...。

本周,我们请来了AR,VR、机器人、机器视觉等各个领域的业内大牛,来给大家讲解最新的技术趋势,及发展现状,大家赶紧报名听课吧!AR显示的未来,详解波导光学技术,硬创公开课预告嘉宾,王耀彰,北京灵犀微光技术合伙人;毕业于北京大学物理学院,曾在北京大学量子电子学研究所从事飞秒光梳光频标的项目工作,后参与组建灵犀AR技术团队,灵犀AR在其成...。

双迪众创美业是从事皮肤管理服务的品牌,公司推出的服务项目多样、收费标准合理,给消费者带去耳目一新的护理体验,许多顾客给出肯定性的评价,而品牌也因此声名远播,这一现象很快引起创业人士的兴趣,他们中的一些人准备介入行业发展,向本站提出双迪众创美业加盟费多少的问题,针对该问题本文将作出清晰解答,给有需要的读者提供帮助,双迪众创美业加盟费多少...。

从毕业后我进入了人生的很重要的一个阶段,那就是工作,开始是进入小公司的,也让我对小公司有一个了解,首先,也是我们所有人最关注的工资,在小公司里面工资相对大公司通常会是很低得,在小公司一般也会有一两个牛人在公司支撑,这样的人公司还是比较高的,其余的都很低的,并且我进的公司基本上五险一金都没有的,加班,那也是经常的事情,一个是能力不足加班...。

随着短视频时代的到来,视频社交正在成为一个现象级风口,逐渐代替文字、图片成为了人们吸收新鲜事物或是展现自己的一大媒介,近年来,各类视频软件层出不穷,国内的抖音、快手、火山等视频APP,国外的Twitch、InstagramLive、FacebookLive......似乎每个平台都在尝试直播,而亚马逊推出新服务AmazonLive证明...。

特雷杨附条件交易去湖人拿到3亿续约合同高管:这个价码就离谱,湖人,库里,老鹰队,特雷杨

据商务部网站7月15日信息,商务部资讯发言人就诉美,通胀增添法,世贸争端案答记者问,问,据悉,中国就美国,通胀增添法,新动力汽车补贴等措施向世贸组织提出设立专家组恳求,是否请您引见详细状况,答,中国新动力汽车产业开展为世界动力绿色转型、应答气象变动作出了关键奉献,为保养中国新动力汽车产业开展权力,3月26日,中方将美国,通胀增添法,无...。

全球时报综合报道,澳大利亚,悉尼先驱晨报,2日报道称,知情人士泄漏,澳大利亚总理阿尔巴尼斯选择不参与行将在华盛顿举办的北约峰会,而是派出由澳大利亚副总理兼国防部长马尔斯率领的代表团参会,悉尼先驱晨报,报道称,阿尔巴尼斯原本估量与日本、韩国和新西兰等所谓,印太四国,成员独特参与9日开局的北约成立75周年纪念峰会,报道称,在未能确认峰...。

孩子矮小长不高,生长激素要不要打?,矮小症

长沙医学院让学生入住未完工宿舍楼?湖南省教育厅回应,学校,长沙医学院,湖南省教育厅

数学这门功课对很多人来说就像是噩梦吧,如果从小基础没打好那么之后学会数学是一件很吃力事情,小编今天给大家推荐适合三年级数学游戏有哪些,每一款游戏都很适合让学生锻炼数学思维,从小对数学有一定的兴趣,长大以后成为数学大神不再是梦想,快来下载游戏让孩子试一试吧!,数学华容道,游戏由数字合并和游戏拼图结合而成,非常考验玩家的思维逻辑能力,在每...。

全球顶尖科技盛会CES2021正式开展,5G板块望受关注全球顶尖科技盛会,2021年国际消费类电子产品展览会,CES2021,于美国时间1月11日,14日以数字化的线上方式举办,整个展览划分为5G、智能城市、数字医疗和智能交通四大重点板块,据悉,5G将主导2021年CES的讨论,业内人士指出,随着国家继续加码5G建设,有助于快速带动相...。

一个新兴产业的诞生,往往对应着巨头企业一个新业务部门的出生,2018年3月,百度宣布进行架构调整,百度度秘事业部、硬件生态渠道部和RavenStudio工作室共同组成智能生活事业群组,SmartLivingGroup,SLG,,当时的百度集团总裁兼首席运营官陆奇出任SLG总经理,至此,百度盯上,智能生活,为众人皆知,在智能生活领域,与...。

2017年,工信部正式颁布云牌照监管政策,让很多企业在合规路上如履薄冰,所幸393张云牌照让主流云厂商全部上岸,可这一年,烧钱的价格战让大批企业负重前行,2018年,云行业价格战减缓,合规不再是主题,这一年,科技领域最大的趋势就是云和AI、IoT、自动驾驶、边缘计算、芯片、5G的结合更加紧密,重回技术路线;这一年,贸易摩擦,让,自主可...。

发表在专业问答2023,3,210,23展示机型信息,品牌型号,当贝X3系统版本,当贝OS2.0当贝X3调整画面大小可以通过设置中的画面缩放功能进行调整,总共可以分为三步,下面为当贝X3怎么调整画面大小的详细步骤做具体说明,当贝X3怎么调整画面大小方法一,画面缩放1.打开投影设置在当贝X3投影仪上点击打开投影仪的设置界面;2.选择画面...。
