ICML 2019 (icml2024)
雷锋网 AI 科技评论按,本文作者 张拳石 ,上海交通大学副教授,研究方向为机器学习、计算机视觉,本文首发于 知乎 ,雷锋网 AI 科技评论获其授权转载。以下为正文内容。
本来想把题目取为「从炼丹到化学」,但是这样的题目太言过其实,远不是近期可以做到的,学术研究需要严谨。但是,寻找适当的数学工具去建模深度神经网络表达能力和训练能力,将基于经验主义的调参式深度学习,逐渐过渡为基于一些评测指标定量指导的深度学习,是新一代人工智能需要面对的课题,也是在当前深度学习浑浑噩噩的大背景中的一些新的希望。
这篇短文旨在介绍团队近期的 ICML 工作——「Towards a Deep and Unified Understanding of Deep Neural Models in NLP」(这篇先介绍 NLP 领域,以后有时间再介绍类似思想解释 CV 网络的论文)。这是我与微软亚洲研究院合作的一篇论文。其中,微软研究院的王希廷研究员在 NLP 方向有丰富经验,王老师和关超宇同学在这个课题上做出了非常巨大的贡献,这里再三感谢。
大家说神经网络是「黑箱」,其含义至少有以下两个方面:一、神经网络特征或决策逻辑在语义层面难以理解;二、缺少数学工具去诊断与评测网络的特征表达能力(比如,去解释深度模型所建模的知识量、其泛化能力和收敛速度),进而解释目前不同神经网络模型的信息处理特点。
过去我的研究一直关注第一个方面,而这篇 ICML 论文同时关注以上两个方面——针对不同自然语言应用的神经网络,寻找恰当的数学工具去建模其中层特征所建模的信息量,并可视化其中层特征的信息分布,进而解释不同模型的性能差异。
其实,我一直希望去建模神经网络的特征表达能力,但是又一直迟迟不愿意下手去做。究其原因,无非是找不到一套优美的数学建模方法。深度学习研究及其应用很多已经被人诟病为「经验主义」与「拍脑袋」,我不能让其解释性算法也沦为经验主义式的拍脑袋——不然解释性工作还有什么意义。
研究的难点在于对神经网络表达能力的评测指标需要具备「普适性」和「一贯性」。首先,这里「普适性」是指解释性指标需要定义在某种通用的数学概念之上,保证与既有数学体系有尽可能多的连接,而与此同时,解释性指标需要建立在尽可能少的条件假设之上,指标的计算算法尽可能独立于神经网络结构和目标任务的选择。
其次,这里的「一贯性」指评测指标需要客观的反应特征表达能力,并实现广泛的比较,比如
1. 诊断与比较同一神经网络中不同层之间语义信息的继承与遗忘;
2. 诊断与比较针对同一任务的不同神经网络的任意层之间的语义信息分布;
3. 比较针对不同任务的不同神经网络的信息处理特点。
具体来说,在某个 NLP 应用中,当输入某句话 x=[x1,x2,…,xn] 到目标神经网络时,我们可以把神经网络的信息处理过程,看成对输入单词信息的逐层遗忘的过程。即,网络特征每经过一层传递,就会损失一些信息,而神经网络的作用就是尽可能多的遗忘与目标任务无关的信息,而保留与目标任务相关的信息。于是,相对于目标任务的信噪比会逐层上升,保证了目标任务的分类性能。
我们提出一套算法,测量每一中层特征 f 中所包含的输入句子的信息量,即 H(X|F=f)。当假设各单词信息相互独立时,我们可以把句子层面的信息量分解为各个单词的信息量 H(X|F=f) = H(X1=x1|F=f) + H(X2=x2|F=f) + … + H(Xn=xn|F=f). 这评测指标在形式上是不是与信息瓶颈理论相关?但其实两者还是有明显的区别的。信息瓶颈理论关注全部样本上的输入特征与中层特征的互信息,而我们仅针对某一特定输入,细粒度地研究每个单词的信息遗忘程度。
其实,我们可以从两个不同的角度,计算出两组不同的熵 H(X|F=f)。
(1)如果我们只关注真实自然语言的低维流形,那么 p(X=x|F=f) 的计算比较容易,可以将 p 建模为一个 decoder,即用中层特征 f 去重建输入句子 x。(2)在这篇文章中,我们其实选取了第二个角度:我们不关注真实语言的分布,而考虑整个特征空间的分布,即 x 可以取值为噪声。在计算 p(X=x,F=f) = p(X=x) p(F=f|X=x) 时,我们需要考虑「哪些噪声输入也可以生成同样的特征 f」。举个 toy example,当输入句子是「How are you?」时,明显「are」是废话,可以从「How XXX you?」中猜得。这时,如果仅从真实句子分布出发,考虑句子重建,那些话佐料(「are」「is」「an」)将被很好的重建。而真实研究选取了第二个角度,即我们关注的是哪些单词被神经网络遗忘了,发现原来「How XYZ you?」也可以生成与「How are you?」一样的特征。
这时,H(X|F=f) 所体现的是,在中层特征 f 的计算过程中,哪些单词的信息在层间传递的过程中逐渐被神经网络所忽略——将这些单词的信息替换为噪声,也不会影响其中层特征。这种情况下,信息量 H(X|F=f) 不是直接就可以求出来的,如何计算信息量也是这个课题的难点。具体求解的公式推导可以看论文,知乎上只放文字,不谈公式。
首先,从「普适性」的角度来看,中层特征中输入句子的信息量(输入句子的信息的遗忘程度)是信息论中基本定义,它只关注中层特征背后的「知识量」,而不受网络模型参数大小、中层特征值的大小、中层卷积核顺序影响。其次,从「一贯性」的角度来看,「信息量」可以客观反映层间信息快递能力,实现稳定的跨层比较。如下图所示,基于梯度的评测标准,无法为不同中间层给出一贯的稳定的评测。

下图比较了不同可视化方法在分析「reverse sequence」神经网络中层特征关注点的区别。我们基于输入单词信息量的方法,可以更加平滑自然的显示神经网络内部信息处理逻辑。

下图分析比较了不同可视化方法在诊断「情感语义分类」应用的神经网络中层特征关注点的区别。我们基于输入单词信息量的方法,可以更加平滑自然的显示神经网络内部信息处理逻辑。

基于神经网络中层信息量指标,分析不同神经网络模型的处理能力。我们分析比较了四种在 NLP 中常用的深度学习模型,即 BERT, Transformer, LSTM, 和 CNN。在各 NLP 任务中,BERT 模型往往表现最好,Transformer 模型次之。
如下图所示,我们发现相比于 LSTM 和 CNN,基于预训练参数的 BERT 模型和 Transformer 模型往往可以更加精确地找到与任务相关的目标单词,而 CNN 和 LSTM 往往使用大范围的邻接单词去做预测。

进一步,如下图所示,BERT 模型在预测过程中往往使用具有实际意义的单词作为分类依据,而其他模型把更多的注意力放在了 and the is 等缺少实际意义的单词上。
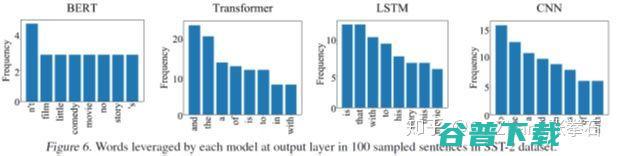
如下图所示,BERT 模型在 L3-L4 层就已经遗忘了 EOS 单词,往往在第 5 到 12 层逐渐遗忘其他与情感语义分析无关的单词。相比于其他模型,BERT 模型在单词选择上更有针对性。

我们的方法可以进一步细粒度地分析,各个单词的信息遗忘。BERT 模型对各种细粒度信息保留的效果最好。

回国以后,身份从博后变成了老师,带的学生增加了不少,工作量也翻倍了,所以一直没有时间写文章与大家分享一些新的工作,如果有时间还会与大家分享更多的研究,包括这篇文章后续的众多算法。信息量在 CV 方向应用的论文,以及基于这些技术衍生出的课题,我稍后有空再写。
顺便做个广告,欢迎有能力的学生来实验室实习,同时也招博后。目前我的团队有 30 余人,其中不少同学是外校全职访问实习生。我一般会安排每三四人为一个团队做一个课题,由于访问实习生往往不用为上课而分心,可以全天候做实验室工作,在经过一定训练之后往往会担任团队领导。
版权文章,未经授权禁止转载。详情见 转载须知 。

本文地址: https://www.gpxz.com/article/88faa985aaa6251c3307.html



喜马拉雅是国内领先的音频分享平台,汇集了有声小说、儿童故事、相声评书、京剧戏曲、新闻段子、广播电台等数亿条免费声音内容,听书、听小说、听故事、听儿歌、听音乐,为您找到每一天的精神食粮!

惠州市金达电源电池科技有限公司是广东省蓄电池行业优质供应商之一,专注机车启动电池,电动车动力电池,监护仪蓄电池,蓄电池厂家,储能备用电池,工业仪器用电池20年,一直以来都注重优质产品供应与服务。

钛阳广告装潢联系电话:13831314489

智享华网致力于为用户提供全面的科技资讯与生活指南,帮助您在现代生活中实现更高效的智能体验。我们聚焦于智能家居、电子产品评测、健康科技等领域,提供最新的产品信息、实用技巧和行业动态,让您随时掌握科技趋势

郑州玉都环保设备有限公司坐落于中国的交通枢纽中心郑州,是中原地区一家大规模的塑料容器生产厂家销售企业。 公司主要产品有:塑料水箱、PE水箱、加药箱、化工防腐储罐、塑胶水塔、周转箱、食品级储罐、塑料桶、腌制桶、锥形储罐、塑料水塔、酸洗槽、大型立式储罐、加药装置、外加剂复配设备、聚羧酸合成设备、酸碱化工储罐、PP焊接储罐、PE储罐、搅拌罐等塑料防腐容器;酸雾吸收塔、pp反应釜,真空罐,缓冲罐等塑料化工环保设备。另承接大型塑料定制产品。 郑州玉都环保设备有限公司产品严格选用优质进口塑料颗粒为原料并按照“中华人民共和国GB9687-88质量标准”为准制造。 郑州玉都环保设备有限公司拥有技术研发中心,具备丰富的研发能力可按不同用途进行各种设计和制造。近年来,为南水北调工程、河南城际高铁高速等国内大型工程配套提供了各种不同规格的塑料储罐产品及相关设备,为甲方基础建设做出贡献。另为多家化工企业提供环保治理产品及方案!欢迎新老用户咨询! 郑州玉都环保设备有限公司本着“创新科技、真情服务”的企业经营理念,倡导

www.7.biz|商业搜索引擎,是中小企业实现采购搜索和网络营销的B2B电子商务平台。帮助中小企业更快,更有效的达成交易。

湖北五三长新鼓风机制造有限公司

九八五资源网打造国内优质游戏资源技术共享平台,分享各种游戏知识等问题解答,各类资源等为用户提供优质服务。


【海投网2025校园招聘】为高校应届生网罗最全面的宣讲会、招聘、实习等校招求职信息,帮助大学毕业生找到最合适的工作,覆盖北京、上海、广州、武汉、西安、成都、南京、合肥、济南、长沙、天津、郑州、杭州、重庆、沈阳、福州、南昌、长春、哈尔滨、石家庄、太原、昆明、兰州、南宁、贵阳、海口、银川、西宁、呼和浩特、乌鲁木齐、拉萨等地区。

NBA2K14游戏专题;提供NBA2K14中文版下载,NBA2K14攻略大全,NBA2K14汉化补丁,NBA2K14视频解说,攻略视频,修改器,汉化下载,完美存档,MOD,配置,教学,截图,壁纸等资料。更多《NBA2K14》相关内容尽在游侠网。

云趣校服系统专门为校服企业量身打造各种校服系统应用,包含校服征订系统、中小学校服订购管理系统、校服监管防伪码系统等


近日,《克苏鲁的呼唤》TRPG创始人、《毁灭战士》与《雷神之锤》设计师SandyPetersen在其个人社交平台公开发声,强烈支持Steam创始人GabeNewell(“G胖”)。

在国内消费规模不断的壮大和提升下,为其经营之路赢得了广泛的市场空间和潜力,其中内衣类的产品,在市场刚需的影响下,其产业的发展更是轻松壮大,珍妮芬内衣实力品牌传授,自有研发基地的指导,在多地的市场上均是得到了无数消费者的欢迎,全国诚邀加盟商,那么珍妮芬内衣怎么加盟,有哪些扶持,店面经营产品系列多,内衣、家居服、泳衣、打底衫,以厂家直供的...。

11月28日,百度灵医智惠与浙江孚宝智能科技有限公司,以下简称,孚宝机器人,签署战略合作协议,双方将发挥各自技术、产品、市场优势,推动医疗康养机器人的技术创新和服务升级,为智慧康养产业注入创新动能,现场,百度集团资深副总裁、大健康事业群总裁何明科,浙江孚宝智能科技有限公司创始人、董事长兼CEO贾国强出席并见签,百度智慧医疗总经理刘军...。

先天或者后天导致的事故,都有可能会形成残疾,如此一来参与社会工作的时候便会有诸多不便和限制,于是很多人都选择了自主创业,先不论个人的行动力如何,适合残疾人创业的项目可以先介绍一番,残疾人创业项目有哪些,残疾人适合的创业点子介绍请看下文,1、家庭旅馆当旅游成了大多数人纾解心情环节压力的休闲方式的时候,旅馆和宾馆就成了大家需求量比较大的项...。

1、还可以GT16L官网报价为1327万起,GT属于中低端小轿车,能源很微弱,但别克的油耗不时是致命伤,由于自身他的车身重假设油耗大,车身品质必需相对就高了外部装璜让人觉得很好,弱小的安吉星系统确实是个好用的物品,2、好稳固性不错,口碑还可以,12款别克英朗gt16手动品质好,捕风捉影,老款英朗也就是大家所说的英朗GT确实是一台不折不...。

宾利新动力车规划曝光宾利CEOAdrianHallmark近日泄漏,未来五年,宾利将推出纯电动汽车,并承诺在2025年前,一切宾利车型都将提供电气化选项,这标记着宾利正踊跃应答电动时代的应战,开局调整其策略规划,以坚持市场竞争力,首款纯电车型有望虽然详细细节尚未地下,但有信息指出,宾利极有或者基于新一代慕尚车型打造一款纯电动版,这款车...。

全球网报道,2024年7月2日,国务院台办发言人陈斌华答记者问,问,关于大陆日前出台,关于依法惩治,台独,固执分子决裂国度、怂恿决裂国度立功的意见,,民进党当局妄称,两岸互不附属,,大陆对台湾没有,司法管辖权,,并吓唬称,90%以上民众都或者遭到涉及,,刻意把赴大陆及港澳地域旅行警示优化到,橙色,岛内言论以为民进党当局此举造成两岸...。

湖南汨罗一河段有堤坝决堤,实拍满载石头卡车进入河中封堵决口7月2日,有网友发视频爆料称,湖南岳阳市汨罗市遭逢暴雨袭击后,罗江镇垉塘村一河流堤坝决口,一辆装满石头的卡车驶入河中阻流,视频颁布者称,,水流太急,填小物品立马就被冲走了,这是最有效最快的阻流方法,7月3日上午,罗江镇政府担任宣传的上班人员接受记者采访时示意,此事是真的,视频...。

6岁孩童在自家店门口游玩摔倒,可怜被一辆货拉拉货车碾轧致死,日前,孩童父亲袁先生向奥一资讯记者示意,事发后,闹事车辆的保险公司启动了相应的赔付,但其以为货拉拉公司作为平台方,有责任和工作解放平台司机的行为,理当承当相应的责任,对此,货拉拉公司关系担任人回应称,6月28日,在政府部门的组织下,平台也已与家眷启动了面谈沟通,面对家眷进一步...。

问道手游自上线以来一直受到广大游戏玩家的喜爱,那么财神究竟怎么杀呢?这里绿色资源网小编为大家带来问道手游财神击杀具体规则及技巧分享,喜欢的朋友不要错过哟!问道手游财神怎么杀财神打法财神身边

ColorMC是一个我的世界全平台JAVA版启动器,我们直接使用自己的游戏账号登录就好了,或者使用微软账号登录,然后到里面还可以加载其它模组的。

局域网助手(LanHelper),局域网助手LanHelper中文版专门为高效率的局域网管理而设计,同时不需要任何服务端软件,节省您的时间和金钱,使您的网络管理更加轻松,您可以免费下载。

从输入关键词,到百度给出搜索结果的过程,往往仅需几毫秒即可完成,百度是如何在浩如烟海的互联网资源中,以如此之快的速度将您的网站内容展现给用户?这背后蕴藏着什么样的工作流程和运算逻辑?事实上,百度搜索引擎的工作并非仅仅如同首页搜索框一样简单,搜索引擎为用户展现的每一条搜索结果,都对应着互联网上的一个页面,每一条搜索结果从产生到被搜索引擎...。

苹果新品发布会已刷屏数日,9月9日,传说中的iPhone6s、iPadPro、平民版,土豪Watch,、甚至新一代AppleTV机顶盒可能会伴随着会场7000人的欢呼及雷锋网编辑的彻夜未眠汹涌而来,等待之际,我们对新产品的,历代前任,做了销量统计和市场前景分析,喜新不厌旧,就是这样的一百分媒体,平民版,土豪Watch,你买不买,听多了...。

在当前的新能源汽车行业里,三元锂电池和磷酸铁锂电池是最为主流的两种电池类型,从行业普遍的评价来看,三元锂电池在性能方面备受好评,而磷酸铁锂电池在可靠性方面却受到了质疑,12月14日晚上8点,极氪发布了自研的磷酸铁锂电池——金砖电池,试图扭转磷酸铁锂电池的既有印象,据极氪智能科技CEO安聪慧介绍,金砖电池是,全球体积利用率最高、充电速度...。

发表在爱普生投影仪2024,6,612,54当贝X5SPro是最新上市的家用投影设备,价格非常接近爱普生TW6280T,那么爱普生TW6280T和当贝X5SPro区别有哪些呢,下面就全面对比分析,看看爱普生TW6280T和当贝X5SPro哪款投影仪的性能配置更强,更适合家用,一、爱普生TW6280T和当贝X5SPro区别有哪些1.光机...。

央视网信息,11月8日,在黑龙江省伊春市丰沟林场,一只体型硕大的老虎悠然得意的出如今了落满白雪的公路之上,视频中,这只老虎独自慢吞吞的向前行走,时不断的俯视到处张望,好像在寻觅着猎物,而这一幕正好被左近单位的值班人员发现,并记载了上去,发现这只西南虎后,值班人员立刻报了警,关系部门接到通知后,迅速劝诫居民们留意安保,目前,这只成年家养...。
