快试试这个Kaggle大数据集高效访问教程 数据太多而无法使用 (快试试这个家常烧饼做法)
译者:AI研习社( 季一帆 )
双语原文链接: Tutorial on reading large>大规模数据集

我敢肯定,你在解决某些问题时,一定报怨过没有足够的数据,但偶尔也会抱怨数据量太多难以处理。本文探讨的问题就是对超大规模数据集的处理。
在数据过多的情况下,最常见的解决方案是根据RAM采样适量数据,但这却浪费了未使用的数据,甚至可能导致信息缺失问题。针对这些问题,研究人员提出多种不同的非子采样方法。需要注意的时,某一方法是无法解决所有问题的,因此在不同情况下要根据具体需求选择恰当的解决方案。
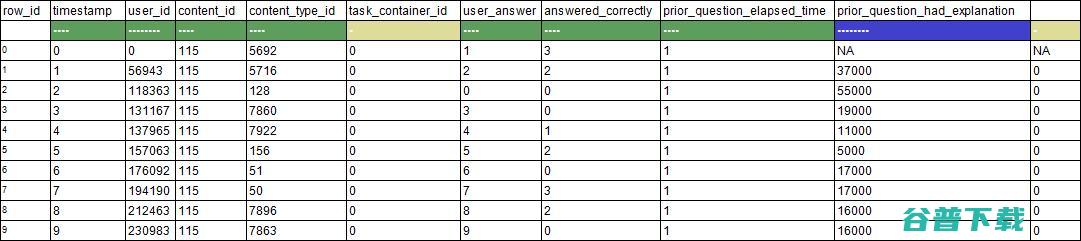
本文将对一些相关技术进行描述和总结。由于 Riiid! Answer Correctness Prediction 数据集由10列,超1亿行的数据组成,在Kaggle Notebook中使用pd.read_csv方法读取会导致内存不足,因此本文将该数据集做为典型示例。
不同安装包读取数据的方式有所不同,Notebook中可用方法包括(默认为Pandas,按字母表排序):
除了从csv文件读取数据外,还可以将数据集转换为占有更少磁盘空间、更少内存、读取速度快的其他格式。Notebook可处理的文件类型包括(默认csv,按字母表排序):
请注意,在实际操作中不单单是读取数据这么简单,还要同时考虑数据的下游任务和应用流程,综合衡量以确定读取方法。本文对此不做过多介绍,读者可自行查阅相关资料。
同时,你还会发现,对于不同数据集或不同环境,最有效的方法往往是不同的,也就是所,没有哪一种方法就是万能的。
后续会陆续添加新的数据读取方法。
方法
我们首先使用Notebook默认的pandas方法,如前文所述,这样的读取因内存不足失败。
import pandas as pdimport dask.dataframe as dd# confirming the default pandas doesn't work (running thebelow code should result in a memory error)#>

是最常用的数据集读取方法,也是Kaggle的默认方法。Pandas功能丰富、使用灵活,可以很好的读取和处理数据。 使用pandas读取大型数据集的挑战之一是其保守性,同时推断数据集列的数据类型会导致pandas> 帮助文档:
Dask介绍
Dask提供并行处理框架对pandas工作流进行扩展,其与Spark具有诸多相似之处。 帮助文档:
Datatable介绍
受R语言data.table的启发,python中提出,该包可快速读取大型数据集,一般要比pandas快得多。值得注意的是,该包专门用于处理表格数据集,能够快速读取大规模的表格数据集。 帮助文档:
|









本文地址: https://www.gpxz.com/article/9cb2757b3934de4a061a.html



天猫理想生活上天猫

LOL网址导航网是专业的上网导航网站,精心收录各类优质热门网站信息,同时提供天气、快递、违章等各种生活便民查询工具网址,为您提供安全便捷的上网导航服务,现已被众多网友设为上网主页,网址导航大全首选LOL网址导航.

寿司日语在线课程体系,标配化课后练习及考前预测点题,个性化达成不同阶段日语学习目标,轻松学日语

IT易学网是一个专注于综合IT技术领域的在线教育平台,互联网技术牛人通过在线、面授、一对一让你学习国内领先的IT技术,如:软件开发、数据库管理、云计算与虚拟化以及厂商认证与辅导等课程。

华暖网-网上贸易、综合网上购物平台、家电、空调、洗衣机、空气能热水器、数码通讯、供应讯,电子商务,信息行业资内贸,数码等批发零售分销站!
机床有限公司")
丰和(天津)机床有限公司

星康游戏网为广大游戏玩家提供最新、最全、最热门的游戏攻略,覆盖手机游戏、端游、页游等全平台内容。无论是新手还是高手,这里都有你需要的游戏攻略和技巧,一站式满足游戏需求,轻松成为游戏达人

电梯模型,教学电梯模型,电梯教学模型,电梯检测模型是上海顶邦教育设备制造有限公司的重点产品,如果您有什么需求或建议的话请联系我们,服务热线:021-36334717,我们将很乐意为您效劳!

水滑石|水滑石厂家|水滑石价格|康高特水滑石,400-600-8953,多年水滑石生产,有型材钙锌稳定剂用水滑石,管材钙锌稳定剂用水滑石等18个品种。

寻古文化是一个提供字画作品、书籍文物等艺术品的超高清大图网站。包含古现代艺术家完整全景图,可微喷印刷的素材。并且提供印刷复制复刻服务。

足球经理2012游戏专题;提供足球经理2012中文版下载,足球经理2012攻略大全,足球经理2012汉化补丁,足球经理2012视频解说,攻略视频,修改器,汉化下载,完美存档,MOD,配置,教学,截图,壁纸等资料。更多《足球经理2012》相关内容尽在游侠网。

定兴县宏达财会办公用品供应处是一家从事银行点钞练功券,外币练功券,调款包,ATM钞箱包系列,尾零箱,翻打传票及其它各种银行机具生产、开发、销售和服务于一体的综合性企业。


古往今来,不管社会是处于动荡不安的状态还是和平的年代,人们对于吃这件事都是非常重视的,尤其是在这个餐饮行业肆意发展的时代,小吃行业嫣然已经成为我国较具智慧之选价值的项目,面对着诱人的空白的商机市场,不少企业都在蓄势待发,其中当属恒记冰室港式小吃,那么,恒记冰室港式小吃的加盟怎么样,恒记冰室加盟店条件是什么,恒记冰室其总部屹立在繁华的上...。

进入2021年,并购大潮下行业的集中度和成熟度不断加强,细分行业的独角兽公司正浮出水面,而在餐饮数字化、实时通信领域,这种路径已经逐渐成型,此外,单纯的财务融资已经不能满足创业公司拓展市场空间的需求,腾讯、字节跳动仍在适时出手,阿里口碑全资收购收购美味不用等据多个独立消息源报道,本月,阿里巴巴已于2020年下半年通过旗下本地生活服务平...。

11月29日,滴滴在其官网发布2024年三季度业绩报告,延续了前两个季度的高质量稳健发展,三季度,包括中国出行和国际业务在内的核心平台交易量为41.18亿单,较去年同期增长15.1%,其中,中国出行总单量为31.83亿单,较去年同期增长10.6%;国际业务总单量为9.35亿单,较去年同期增长33.4%,中国出行及国际业务日均单量分别达...。

如果说工业互联网是美国先进制造的重要基础,德国工业4.0的关键支撑,日本制造业的发展目标,那么对于中国而言,工业互联网就是制造业数字化转型的重要手段,据全球移动通信系统协会预测,2016年至2025年间,工业互联网设备联网数量将从24亿增加到138亿,预计到2023年将超过消费物联网设备联网数量,可见,工业互联网大潮已席卷全球,安全是...。

最近,MenloVentures针对拥有50名以上员工的公司的600名企业IT决策者进行调查,发布了一份名为,2024年生成式AI现状,的企业市场报告,2024年,生成式AI市场的整体支出飙升至138亿美元,相比2023年的23亿美元增长了6倍以上,体现出企业对AI工具的强大信心和需求,报告显示,72%的IT决策者计划在未来更广泛地采...。

一、讲卫生戴口罩口罩依旧是预防呼吸道传染病的重要武器即使是夏日炎炎也要坚持正确佩戴口罩,密闭空间,如电梯、公交、地铁等,必须佩戴口罩,汗湿后要及时更换,坚决做到疫情不退,口罩不摘!二、勤洗手不可少尽量减少触碰公共设施和物品,外出归来、用餐前、接触口罩及其他物品后等都要洗手,也可携带免洗手消毒剂,随时保持手卫生,三、打喷嚏讲礼仪打喷嚏时...。

1、在这次抗洪救灾中他以身殉职了,2、小李的爸爸在执行任务时不幸殉职,3、他去年在抗洪抢险中不幸以身殉职,4、他一直照顾因公殉职部属的家人,可说是仁至义尽,5、蒋筑英同志不幸在工作时以身殉职,6、孔繁森同志不幸以身殉职,7、白求恩大夫为了中国人民的解放事业,不幸以身殉职,8、令我们深感悲痛的是,她以身殉职了.9、去年春上到北戴河,后来...。

发表在其它家用投影仪品牌2024,11,2616,50懂影Q8是一款机身方正的投影仪,具体这款投影仪有什么样的画质和性能配置呢,下面就来全方面了解这款投影仪,看看懂影Q8投影仪怎么样,有什么优缺点,是否可以满足家用需求,懂影Q8投影仪怎么样,1.光学参数懂影Q8采用的是LCD显示技术,有不错的色彩还原度,光源亮度达到3800流明,整体...。
准备工作,百度影棒2S、安卓手机一部打开手机上的浏览器,百度搜索,当贝市场,,进入官网下载,手机版当贝市场,并安装到手机上和手机必须在同一局域网内,二、开启盒子的ADB远程调试,手机版,根据ip地址连接盒子,连接上以后,一般情况下开启,当贝市场会自动安装到盒子上当贝市场安装好之后,就可以随意在当贝里面安装你需要的第三方直播、点播、游戏...。

《午夜》刊登在2024年5月《知音》第15期上,存谢!_蒲苇De文字之旅_新浪博客,蒲苇De文字之旅,

PLECSStandalone是一款由德国的PLECS公司开发的电力电子仿真软件。它为工程师和研究人员提供了一个强大的工具

近日腾讯视频悄悄上线了一起看的功能,也就是说你可以和你的好友一起追剧讨论相关剧情了,那么腾讯视频一起看可以连麦吗?也有一些小伙伴反映自己腾讯视频没有一起看这个功能,这是为啥呢?,腾讯视频一起看可以连麦吗腾讯视频一起看为何进不去

12月3日,2020中国企业数字创新峰会在杭州举行,400位企业CEO、CTO、CIO齐聚一堂,共同探讨企业数字化转型经验,今年新冠疫情爆发,给企业带来不小挑战,到场嘉宾表示,数字化已经成为企业未来发展最大的确定性,本次峰会由阿里云CIO学院主办,据阿里云CIO学院院长洪英介绍,400位嘉宾分别来自央企、国企、民企,都是企业信息化建设...。

2024年DAC同比翻倍,3月28日,在2024淘宝内容电商盛典活动上,淘宝内容电商事业部总经理道放给出了自己的年度目标,这个略显激进的目标背后,折射出的既是淘宝在内容电商领域的决心,也是信心,内容和电商,从加法到乘法过去一年,淘宝内容电商最显性的变化在于,直播和逛逛两大内容场域在组织层面实现打通,二者合并成立了新的淘宝内容电商事...。

代码说明,本页面的认证代码为悟空网盟专用评测代码,站长需懂简单html知识,直接复制代码粘贴到联盟网站相应页面即可使用,本代码不适用于其他广告联盟网站请勿获取!文字认证,文字链接代码认证适用所有类型的广告联盟,复制代码后放在悟空网盟网站首页底部或友情链接位置处,普通认证,普通联盟认证标志适用所有类型的广告联盟,能有效提升悟空网盟的可信...。

央视网信息,11月8日,在黑龙江省伊春市丰沟林场,一只体型硕大的老虎悠然得意的出如今了落满白雪的公路之上,视频中,这只老虎独自慢吞吞的向前行走,时不断的俯视到处张望,好像在寻觅着猎物,而这一幕正好被左近单位的值班人员发现,并记载了上去,发现这只西南虎后,值班人员立刻报了警,关系部门接到通知后,迅速劝诫居民们留意安保,目前,这只成年家养...。

英国奥运冠军拒绝药检,仍加入巴黎奥运,据英国,独立报,8日报道,在去年12月拒绝接受兴奋剂检测一事被曝光后,两届奥运冠军、英国跆拳道静止员杰德·琼斯坚称自己从未经常使用过兴奋剂,报道称,只管拒绝药检可被处以禁赛4年的处分,但在往年巴黎奥运会揭幕前不久,英国反兴奋剂组织仍裁定她,无过失,,而她说自己过后由于脱水造成,没在精气形态,#...。
