为什么深度学习是非参数的


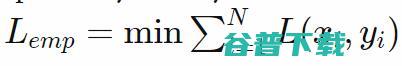 最小化。如果我们的损失函数是负对数似然,将
最小化。如果我们的损失函数是负对数似然,将
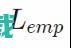 最最小化就意味着计算最大相似估计。
最最小化就意味着计算最大相似估计。
对偏差-方差分解和偏差-方差平衡的简单介绍
 中采得的随机变量,且我们训练的模型
f依赖于
D,记作
中采得的随机变量,且我们训练的模型
f依赖于
D,记作
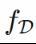
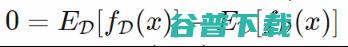 并利用(,)和D的独立性,我们可以将预测的期望平方误差分解为:
并利用(,)和D的独立性,我们可以将预测的期望平方误差分解为:
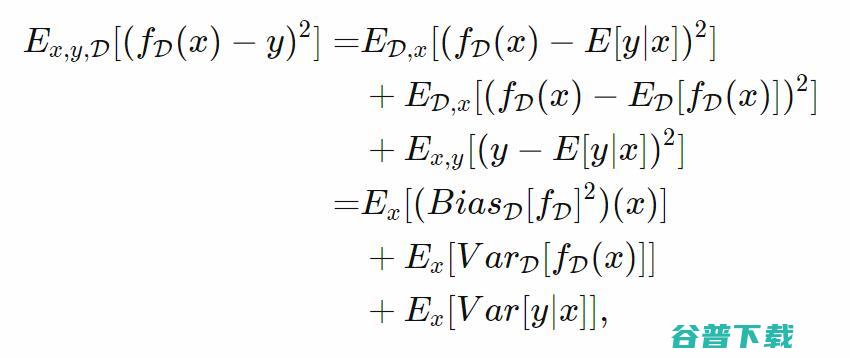
 ,我们可以让方差为0,这样则是极端的欠拟合。
,我们可以让方差为0,这样则是极端的欠拟合。
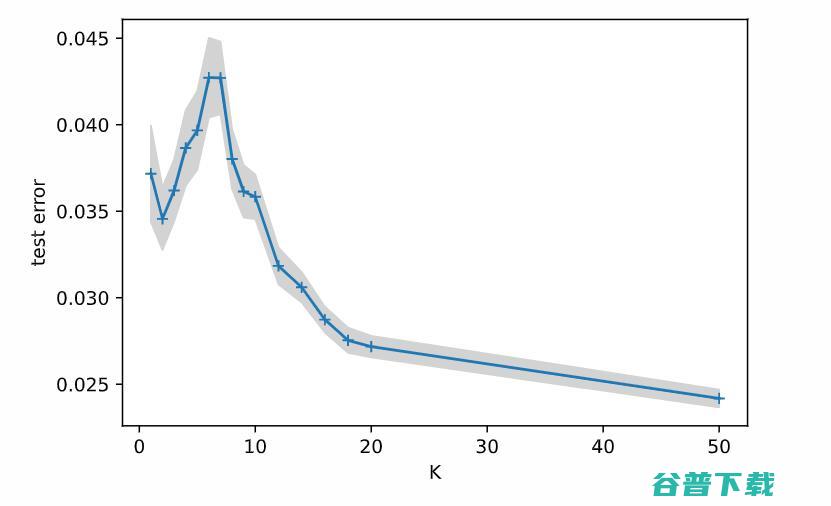
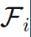 的大小或其VC维的项。此处的典型情况是,一个人想要≥VC-dim个样本,却可能有≤20VC-dim个样本。但请注意,这里参数的数量不是标准的一部分(但可能会影响VC维)。
的大小或其VC维的项。此处的典型情况是,一个人想要≥VC-dim个样本,却可能有≤20VC-dim个样本。但请注意,这里参数的数量不是标准的一部分(但可能会影响VC维)。
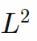 里有弱导数的索伯列夫函数空间
里有弱导数的索伯列夫函数空间
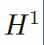 (无论采用何种测度,是x的分布抑或是包含输入的
(无论采用何种测度,是x的分布抑或是包含输入的
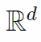 的勒贝格测度),我们可以匹配任意有限样本D上每一点的样本均值,从而可以获得0点态偏差, 但是最小化经验风险是病态的,有无限多的解。
的勒贝格测度),我们可以匹配任意有限样本D上每一点的样本均值,从而可以获得0点态偏差, 但是最小化经验风险是病态的,有无限多的解。
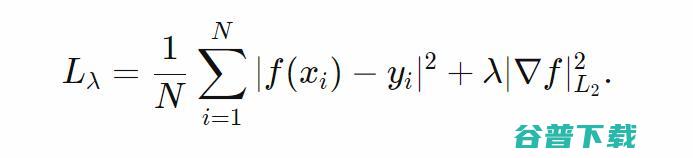
 。我们并不想让方差为0,因为我们的正则化项仅仅是一个半范数)。当然了,Grace Wahba有关正则化回归的研究尤其与保持偏差-方差间的良好平衡相关,特别是与如何寻找到一个合适的值相关。
。我们并不想让方差为0,因为我们的正则化项仅仅是一个半范数)。当然了,Grace Wahba有关正则化回归的研究尤其与保持偏差-方差间的良好平衡相关,特别是与如何寻找到一个合适的值相关。
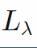
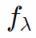

 中将经验最小二乘损失(第一项) 最小化,就可以将前一节中的ansatz函数与嵌套空间Fi联系起来。因此来自递增权重序列
中将经验最小二乘损失(第一项) 最小化,就可以将前一节中的ansatz函数与嵌套空间Fi联系起来。因此来自递增权重序列
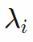
 就给到了我们嵌套的Ansatz空间。
就给到了我们嵌套的Ansatz空间。
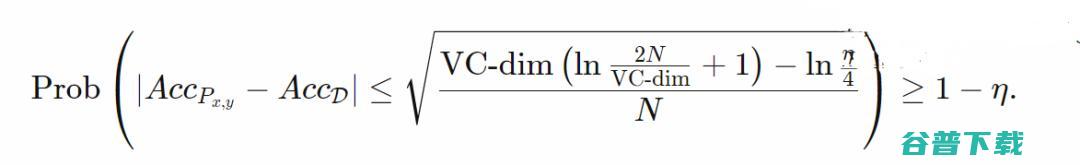
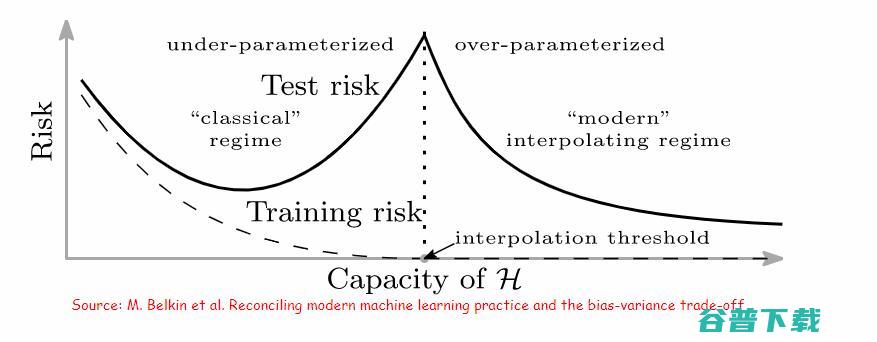
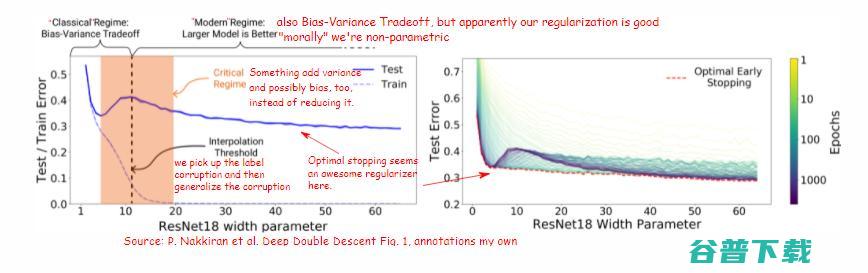
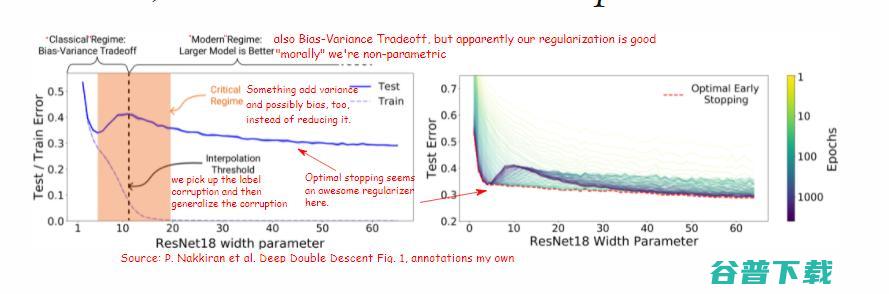
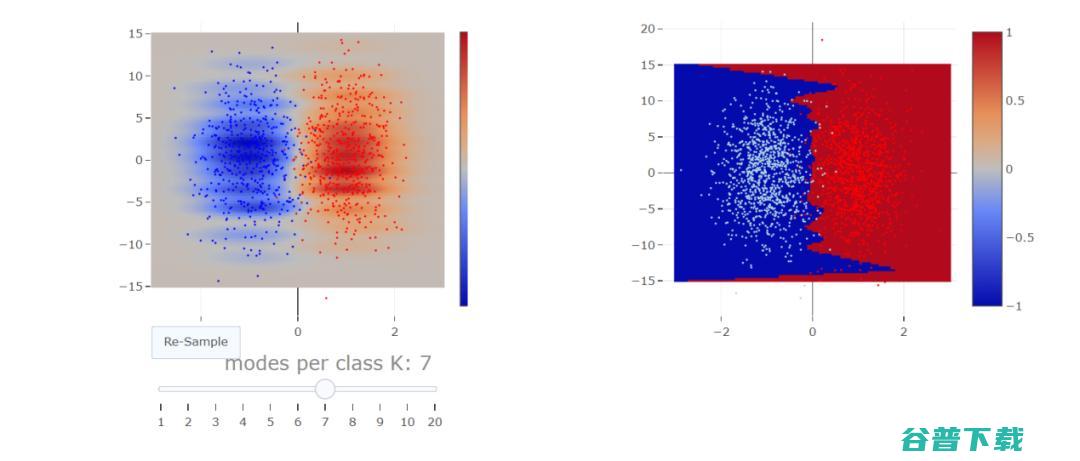
在插值条件中挤出错误标记的数据
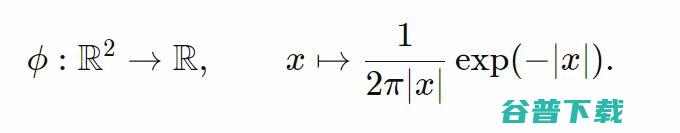
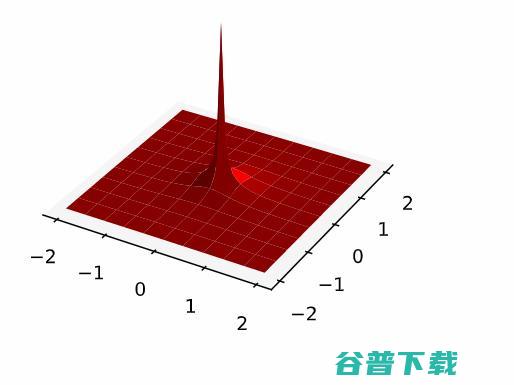

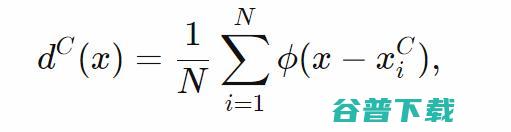
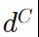 更大的点对每个点进行分类,或者说,如果我们想通过标准化每个点的概率密度来获取概率
更大的点对每个点进行分类,或者说,如果我们想通过标准化每个点的概率密度来获取概率
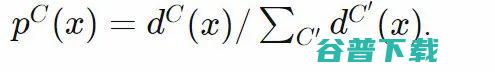
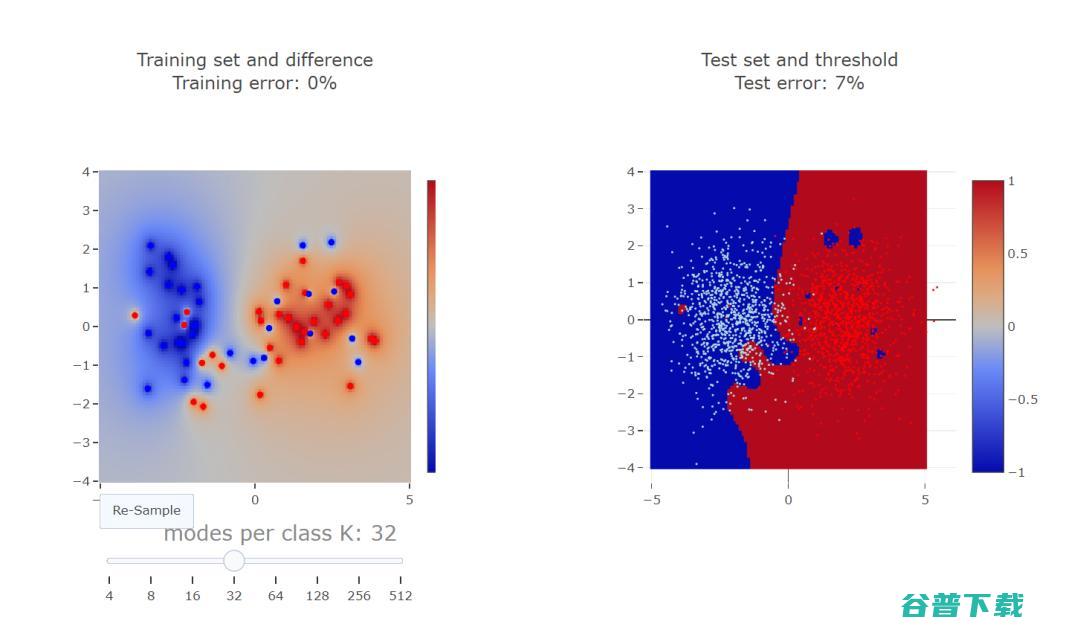
特征噪声类似于标签噪声


 ,当⋅+≥0时,类为1;否则,类为0。如果我们预先知道输入是有界的,我们可以找到类原型
,当⋅+≥0时,类为1;否则,类为0。如果我们预先知道输入是有界的,我们可以找到类原型
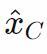
 进行分类。但随后的线性分类器的−1维零空间(null-Space)中的向量,比如我们可以添加到输入中而不改变结果的向量空间
进行分类。但随后的线性分类器的−1维零空间(null-Space)中的向量,比如我们可以添加到输入中而不改变结果的向量空间
 ,可能对这个距离有很大帮助,从而使得
成为对更相关的投影距离
,可能对这个距离有很大帮助,从而使得
成为对更相关的投影距离


版权文章,未经授权禁止转载。详情见 转载须知 。

本文地址: https://www.gpxz.com/article/e00c320e18caf916507b.html



免费家政公司加盟、月嫂公司加盟,开家政公司、家政公司怎么赚钱,找最好月嫂公司、找最好家政公司,聚政网入驻家政公司8万多家、客户找阿姨当天上户快。


4399足球小游戏大全收录了国内外足球类小游戏、实况足球小游戏、功夫足球小游戏、足球小游戏下载、最新足球小游戏。好玩就拉朋友们一起来玩吧!

疯狂食间,专注餐饮品牌创作的一群疯子、餐饮品牌设计公司,提供茶饮品牌设计,主题餐饮设计,主题餐厅设计,餐饮品牌策划设计,画册设计等;以专属形象定制作为餐饮品牌接入点,助力中国互联网+品牌时代,非常期待您的到来,服务热线:0755-23590995

探索三星让您感受品位生活,在这里您可以找到GalaxyZFold6|ZFlip6,GalaxyS24Ultra,GalaxyS24|S24+,GalaxyTabS10系列,GalaxyWatchultra,GalaxyWatch7,三星W24|W24Flip,GalaxyBuds3Pro,GalaxyRing等新品,也可以浏览手机、电视、显示器、冰箱、洗衣机等三星官方产品内容,并获得相关产品服务与支持。

国际装饰网成立以来始终坚持“企业好伙伴,百姓好帮手”的双向运营理念,不断创新,多方合作,全面宣传,全力打造装饰建材家居类行业网站的典范!

康必行海外医疗是医疗旅游领域更值得信赖的出国就医品牌,专注于全球医药大数据以及领先的疾病治疗方案的开发整合,重点业务:丙肝,吉三代,乙肝,TAF,肿瘤,靶向药,抗癌新药,厄达替尼,艾伏尼布,瑞维美尼,恩西地平,索托拉西布,阿达格拉西布,阿培利司,阿那莫林,西多福韦,佩米替尼,他替瑞林等疾病药品,已为数以万计的用户提供了最佳的治疗方案和新药查询,专业医学顾问7x24小时一对一的方式为客户提供免费专业的海外医疗服务。

三祐环保

广州大洋图文数码快印有限公司,专业提供一站式图文快印解决方案,拥有近20年经验的大型数码快印全国连锁品牌店.目前拥有80多家分店,店面遍布在广州,深圳,东莞等地.服务涵括:彩色数码印刷,黑白数码印刷,大幅面写真输出,工程图纸输出,文本装订,商务印刷,网络印刷,图文快印,数码快印,图文打印,数码直印,CAD晒图,CAD出图,CAD彩图,数码打样,大图复印,标书打印,工程图打印,菜谱印刷,服装吊牌印刷等,为用户提供24小时图文印刷及送货服务。

佳秦手游网为您提供丰富的安卓手机游戏下载和应用市场信息。无论是热门手游还是最新应用,您都能在这里找到。我们的手游排行榜和手机游戏大全将帮助您快速找到最适合的游戏,尽享游戏乐趣!

Monica是一款智能助手,具备强大的记忆功能,随时为你提供个性化的支持与建议。无论是日常生活还是工作学习,Monica都能成为你的贴心伙伴,帮助你更高效地完成每一件事。

UPhoto优拍云摄影,免费好用的照片直播软件平台,图片直播云摄影软件,就找优拍云摄影!UPhoto让每个摄影师都能做图片直播,让更多人享受照片直播云摄影乐趣!


暑假在即,很多小玩家们又可能会有很多时间来玩了,那么朋友们可能本着提高孩子智力的目的会希望有一些能够培养数学思维的游戏来让孩子们不仅可以玩,还能在玩的时候得到一些收获,今天小编就给大家准备了几款这样的游戏,玩起来以数字为主,让孩子们玩和学两不误,这类大家肯定都有一定的了解了,怎么玩不必多说,这款游戏就在此基础上增加了很多不同个难度,让...。

网友,深圳城中村租,爆料,最近逛贴吧发现百度贴吧开始大量封禁IDC行业贴吧,以后个人空间商再想蹭百度贴吧搞推广引流和做百度排名怕是越来越难了,深入了解到,百度贴吧这次封禁IDC流量入口,覆盖范围还挺广,像免费空间、虚拟主机、云主机,云服务器、vps等主机行业关键词都被屏蔽,相关贴吧也都被关闭,连带宽,高防,域名都给一块端,全部屏蔽了,...。

餐饮市场上不断地涌现出不同的食品,虽然说这些东西都有自己的特色,但是有的产品没有提高,增加食品的安全,有的产品就会让消费人群吃出亚健康的身体,消费者在食品安全方面要有很多的重视,而将就中式快餐的产品一直都是提高,增加食品的安全健康,是快餐市场的领头羊,品牌的知名度,从而让品牌的地位提升,加盟商想和将就中式快餐共从创造出利益,将就中式快...。

在AI、大数据技术的推动下,银行的传统经营模式正在发生根本性的变化,数据驱动的轻型银行模式随之诞生,而在向数据驱动方向奔驰的路上,如何高效处理海量数据成为一个重要的课题,作为我国银行业数字化转型的先锋军,招行也面临着这样的难题,IT架构转型是数字化创新的基石,而一个可扩展、高性能的数据库是IT基础设施的关键支柱,由此可见数据库之于数字...。

外地期间10月4日晚,也门胡塞武装宣布申明称,今日美英联军对也门多地发起了12次空袭,其中,对萨那发起了4次空袭,对荷台达省发起了7次空袭,对扎马尔省发起了1次空袭,胡塞武装称也门多地遭美英空袭胡塞武装示意,美英的空袭不会阻止他们继续抵制的信心,胡塞武装将继续捍卫也门和也门民众,并将继续展开军事执行,直至以色列完结对加沙地带和黎巴嫩的...。

本文系网易沸点上班室,谈心社,栏目,群众号,txs163,出品,每天降级,开播8.2、豆瓣评分一路稳固下跌到8.6,山河令,火了,有人说,这部剧里有久违的老式武侠浪漫、家国情怀,明星,谈心社,约请到了周子舒的饰演者张哲瀚,采访中,他谈了谈自己对角色的了解,温客行挺像个孩子,周子舒是一个历经沧桑的人,温客行都不必定了解他自己想要什么...。

微顶跑腿是一款提供多种跑腿类别服务的应用程序,包括外卖、快递、代购、送花等。用户可以根据自己的需求选择合适的服务

文,观察者网严珊珊,距离法国国民议会第二轮选举还有几天,首轮上游的极左翼政党国民联盟和法国总统马克龙的两边派联盟之间弛缓相关加剧,国民联盟指导人玛丽娜·勒庞对马克龙近期任命初级官员的执行动员攻打,综非法新社和,政治报·欧洲版,报道,外地期间7月2日,勒庞称据传马克龙正在匆忙任命初级官员,假设是真的,这就是一种,行政政变,,是在法国政...。

长安奔奔是一款性价比拟高的车型,全体品质表现良好,首先,发起机驳回1.3全铝材质,自创了铃木的技术,型号为474Q2,这种技术在羚羊车型上获取了宽泛运行,并且耐用性获取了验证,其次,奔奔的空间表现也很杰出,车身重量到达了1000公斤,用料短缺,外观设计相对欧化,时兴感十足,此外,奔奔的高、宽、劲、晃是其四大特点,其中,车身高度较高,比...。

要在笔记本电脑高低载Photoshop,您可以经过以下步骤启动,1.关上阅读器,进入Adobe官网网站,2.在网站首页,找到并点击,下载Photoshop,按钮,3.依据您的笔记本电脑操作系统选用相应的版本,普通会有Windows和MacOS两个版本供选用,4.接上去,点击,下载,按钮,期待下载实现,下载实现后,您须要启动装置,双击下...。

Rhinoceros中文破解版是一款非常专业的三维建模软件,对于工业设计、机械设计、三维动画等领域,都有着非常重要的作用。

仿25ge封装的APP封装源码-可以封装安卓和IOS源码资源仅供学习研究美工使用,请勿用于商业和非法用途!源码说明安卓以封装A**IOS封装的是描述文件可以去除顶部网址,绿标签名等等很多功能源码截图

说到双人格斗游戏手机版,那简直就是暴力美感的大舞台,特别是双人联机玩的那种,简直是动作游戏爱好者的心头好,跟大家的好朋友一起,在线上开个房间来一场说打就打的公平对决,那感觉就像是身体里的小宇宙突然爆发,今天小编就给大家安利几款,这些游戏不仅能让大家们在线上畅快对战,每一局都紧张,保证让大家俩的格斗之魂熊熊燃烧,1、,墨斗,首先能让大家...。

生态环境2月对辅导类公众帐号设立专门监管机制,4月小程序取消公众号关联限制,5月开通流量主门槛从5000降至500,微信打击,利诱用户分享朋友圈打卡,,微信广告流量主分成政策调整,6月微信发布关于打击,微信营销,外挂的公告,微信严打公众号推广高收益理财内容,8月微信发布洗稿抄袭滥用原创等处理办法,,视频原创声明功能,内测,微信治理第三...。

九月,摆脱了炎热的天气,秋风渐渐吹进了生机勃勃的大学校园,对于中国大学生来说,秋季也是成长的季节,因为火热的校园秋招从九月开始正式拉开序幕,而对于远在美国的大学生Sabbyrina而言,她还没从一段意义非凡的暑期实习中回过神来,因为她进入的公司是许多游戏玩家心中的圣地——暴雪娱乐,Sabbyrina,右一,工作合影暴雪实习生,Bliz...。

开美容院加盟店在前期的资金投入上对比于自己单干,可以控制一定的资金预算并节省开店成本在美容行业,好的美容师是非常重要的,在员工培训方面也需要投入大量物力人力财力,加盟商可以免费进修管理经营课程,也可以送员工进修美容课程...。

中国队,率先冲过终点!,2月5日晚短道速滑混合团体接力决赛后,腾讯3D手语数智人,聆语,,用手语表达了见证中国队获得冠军的激动心情,腾讯3D手语数智人,聆语,作为央视频AI手语翻译官,为这场比赛提供了手语翻译解说服务,见证了中国队在本届赛事中首枚金牌的诞生,让处于无声世界中的特殊人群也能感受到中国举办冰雪赛事的盛况,进一步提升了听障...。
