轻松进行自监督学习 BYOL (可以自我监督的软件)
译者:AI研习社( 季一帆 )
双语原文链接: Easy Self-Supervised Learning with BYOL
自监督学习
在中,经常遇到的问题是没有足够的标记数据,而手工标记数据耗费大量时间且人工成本高昂。基于此,自我监督学习成为深度学习的研究热点,旨在从未标记样本中进行学习,以缓解数据标注困难的问题。子监督学习的目标很简单,即训练一个模型使得相似的样本具有相似的表示,然而具体实现却困难重重。经过谷歌这样的诸多先驱者若干年的研究,子监督学习如今已取得一系列的进步与发展。
在BYOL之前,多数自我监督学习都可分为对比学习或生成学习,其中,生成学习一般GAN建模完整的数据分布,计算成本较高,相比之下,对比学习方法就很少面临这样的问题。对此,BYOL的作者这样说道:
为了实现对比方法,我们必须将每个样本与其他许多负例样本进行比较。然而这样会使训练很不稳定,同时会增集的系统偏差。BYOL的作者显然明白这点:
不仅仅是颜色失真,其他类型的数据转换也是如此。一般来说,对比训练对数据的系统偏差较为敏感。在机器学习中,数据偏差是一个广泛存在的问题(见 facial recognition for women and minorities ),这对对比方法来说影响更大。不过好在BYOL不依赖负采样,从而很好的避免了该问题。
BYOL:Bootstrap Your Own Latent(发掘自身潜能)
BYOL的目标与对比学习相似,但一个很大的区别是,BYOL不关心不同样本是否具有不同的表征(即对比学习中的对比部分),仅仅使相似的样品表征类似。看上去似乎无关紧要,但这样的设定会显著改善模型训练效率和泛化能力:
BYOL最小化样本表征和该样本变换之后的表征间的距离。其中,不同变换类型包括0:平移、旋转、模糊、颜色反转、颜色抖动、高斯噪声等(我在此以图像操作来举例说明,但BYOL也可以处理其他数据类型)。至于是单一变换还是几种不同类型的联合变换,这取决于你自己,不过我一般会采用联合变换。但有一点需要注意,如果你希望训练的模型能够应对某种变换,那么用该变换处理训练数据时必要的。
首先是数据转换增强的编码。BYOL的作者定义了一组类似于SimCLR的特殊转换:
| import randomfrom typing import Callable, Tuplefrom kornia import augmentation as augfrom kornia import filtersfrom kornia.geometry import transform as tfimport torchfrom torch import nn, Tensorclass RandomApply(nn.Module):def __init__(self, fn: Callable, p: float):super().__init__()self.fn = fnself.p = pdef forward(self, x: Tensor) -> Tensor:return x if random.random() > self.p else self.fn(x)def default_augmentation(image_size: Tuple[int, int] = (224, 224)) -> nn.Module:return nn.Sequential(tf.Resize(size=image_size),RandomApply(aug.ColorJitter(0.8, 0.8, 0.8, 0.2), p=0.8),aug.RandomGrayscale(p=0.2),aug.RandomHorizontalFlip(),RandomApply(filters.GaussianBlur2d((3, 3), (1.5, 1.5)), p=0.1),aug.RandomResizedCrop(size=image_size),aug.Normalize(mean=torch.tensor([0.485, 0.456, 0.406]),std=torch.tensor([0.229, 0.224, 0.225]),),) |
上述代码通过实现数据转换,这是一个基于 PyTorch 的可微分的计算机视觉开源库。当然,你可以用其他开源库实现数据转换扩充,甚至是自己编写。实际上,可微分性对BYOL而言并没有那么必要。
接下来,我们编写编码器模块。该模块负责从基本模型提取特征,并将这些特征投影到低维隐空间。具体的,我们通过wrapper类实现该模块,这样我们可以轻松将BYOL用于任何模型,无需将模型编码到脚本。该类主要由两部分组成:
特征抽取,获取模型最后一层的输出。
映射,非线性层,将输出映射到更低维空间。
特征提取通过hooks实现(如果你不了解hooks,推荐阅读我之前的介绍文章 How to Use PyTorch Hooks )。除此之外,代码其他部分很容易理解。
| from typing import Uniondef mlp(dim: int, projection_size: int = 256, hidden_size: int = 4096) -> nn.Module:return nn.Sequential(nn.Linear(dim, hidden_size),nn.BatchNorm1d(hidden_size),nn.ReLU(inplace=True),nn.Linear(hidden_size, projection_size),)class encoderWrapper(nn.Module):def __init__(self,MODEL: nn.Module,projection_size: int = 256,hidden_size: int = 4096,layer: Union[str, int] = -2,):super().__init__()self.model = modelself.projection_size = projection_sizeself.hidden_size = hidden_sizeself.layer = layerself._projector = Noneself._projector_dim = Noneself._encoded = torch.empty(0)self._register_hook()@propertydef projector(self):if self._projector is None:self._projector = mlp(self._projector_dim, self.projection_size, self.hidden_size)return self._projectordef _hook(self, _, __, output):output = output.flatten(start_dim=1)if self._projector_dim is None:self._projector_dim = output.shape[-1]self._encoded = self.projector(output)def _register_hook(self):if isinstance(self.layer, str):layer = dict([*self.model.named_modules()])[self.layer]else:layer = list(self.model.children())[self.layer]layer.register_forward_hook(self._hook)def forward(self, x: Tensor) -> Tensor:_ = self.model(x)return self._encoded |
BYOL包含两个相同的编码器网络。第一个编码器网络的权重随着每一训练批次进行更新,而第二个网络(称为“目标”网络)使用第一个编码器权重均值进行更新。在训练过程中,目标网络接收原始批次训练数据,而另一个编码器则接收相应的转换数据。两个编码器网络会分别为相应数据生成低维表示。然后,我们使用多层感知器预测目标网络的输出,并最大化该预测与目标网络输出之间的相似性。
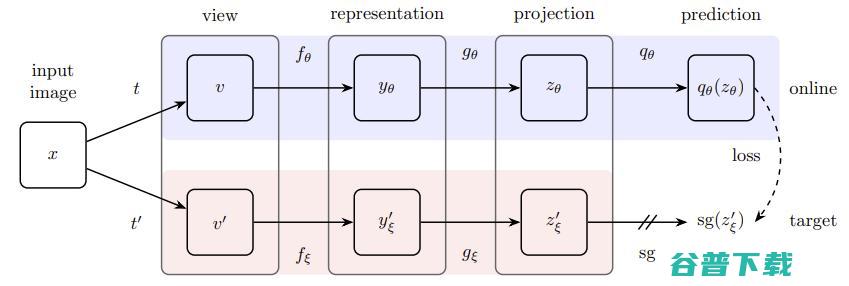
图源: Bootstrap Your Own Latent
也许有人会想,我们不是应该直接比较数据转换之前和之后的隐向量表征吗?为什么还有设计多层感知机?假设没有MLP层的话,网络可以通过将权重降低到零方便的使所有图像的表示相似化,可这样模型并没有学到任何有用的东西,而MLP层可以识别出数据转换并预测目标隐向量。这样避免了权重趋零,可以学习更恰当的数据表示!
训练结束后,舍弃目标网络编码器,只保留一个编码器,根据该编码器,所有训练数据可生成自洽表示。这正是BYOL能够进行自监督学习的关键!因为学习到的表示具有自洽性,所以经不同的数据变换后几乎保持不变。这样,模型使得相似示例的表示更加接近!
接下来编写BYOL的训练代码。我选择使用 Pythorch Lightning 开源库,该库基于PyTorch,对项目非常友好,能够进行多GPU培训、实验日志记录、模型断点检查和混合精度训练等,甚至 在cloud TPU上也支持基于该库运行PyTorch模型 !
| from copy import deepcopyfrom itertools import chainfrom typing import Dict, Listimport pytorch_lightning as plfrom torch import optimimport torch.nn.functional as fdef normalized_mse(x: Tensor, y: Tensor) -> Tensor:x = f.normalize(x, dim=-1)y = f.normalize(y, dim=-1)return 2 - 2 * (x * y).sum(dim=-1)class BYOL(pl.LightningModule):def __init__(self,model: nn.Module,image_size: Tuple[int, int] = (128, 128),hidden_layer: Union[str, int] = -2,projection_size: int = 256,hidden_size: int = 4096,augment_fn: Callable = None,beta: float = 0.99,**hparams,):super().__init__()self.augment = default_augmentation(image_size) if augment_fn is None else augment_fnself.beta = betaself.encoder = EncoderWrapper(model, projection_size, hidden_size, layer=hidden_layer)self.predictor = nn.Linear(projection_size, projection_size, hidden_size)self.hparams = hparamsself._target = Noneself.encoder(torch.zeros(2, 3, *image_size))def forward(self, x: Tensor) -> Tensor:return self.predictor(self.encoder(x))@propertydef target(self):if self._target is None:self._target = deepcopy(self.encoder)return self._targetdef update_target(self):for p, pt in zip(self.encoder.parameters(), self.target.parameters()):pt.data = self.beta * pt.data + (1 - self.beta) * p.data# --- Methods required for PyTorch Lightning only! ---def configure_optimizers(self):optimizer = getattr(optim, self.hparams.get("optimizer", "Adam"))lr = self.hparams.get("lr", 1e-4)weight_decay = self.hparams.get("weight_decay", 1e-6)return optimizer(self.parameters(), lr=lr, weight_decay=weight_decay)def training_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x = batch[0]with torch.no_GRAD():x1, x2 = self.augment(x), self.augment(x)pred1, pred2 = self.forward(x1), self.forward(x2)with torch.no_grad():targ1, targ2 = self.target(x1), self.target(x2)loss = torch.mean(normalized_mse(pred1, targ2) + normalized_mse(pred2, targ1))self.log("train_loss", loss.item())return {"loss": loss}@torch.no_grad()def validation_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x = batch[0]x1, x2 = self.augment(x), self.augment(x)pred1, pred2 = self.forward(x1), self.forward(x2)targ1, targ2 = self.target(x1), self.target(x2)loss = torch.mean(normalized_mse(pred1, targ2) + normalized_mse(pred2, targ1))return {"loss": loss}@torch.no_grad()def validation_epoch_end(self, outputs: List[Dict]) -> Dict:val_loss = sum(x["loss"] for x in outputs) / len(outputs)self.log("val_loss", val_loss.item()) |
上述代码部分源自Pythorch Lightning提供的示例代码。这段代码你尤其需要关注的是training_step,在此函数实现模型的数据转换、特征投影和相似性损失计算等。
实例说明
下文我们将在 STL10数据集 上对BYOL进行实验验证。因为该数据集同时包含大量未标记的图像以及标记的训练和测试集,非常适合无监督和自监督学习实验。STL10网站这样描述该数据集:
通过 Torchvision 可以很方便的加载STL10,因此无需担心数据的下载和预处理。
| from torchvision.datasets import STL10from torchvision.transforms import ToTensorTRAIN_DATASET = STL10(root="data", split="train", download=True, transform=ToTensor())TRAIN_UNLABELED_DATASET = STL10(root="data", split="train+unlabeled", download=True, transform=ToTensor())TEST_DATASET = STL10(root="data", split="test", download=True, transform=ToTensor()) |
同时,我们使用监督学习方法作为基准模型,以此衡量本文模型的准确性。基线模型也可通过Lightning模块轻易实现:
| class SupervisedLightningModule(pl.LightningModule):def __init__(self, model: nn.Module, **hparams):super().__init__()self.model = modeldef forward(self, x: Tensor) -> Tensor:return self.model(x)def configure_optimizers(self):optimizer = getattr(optim, self.hparams.get("optimizer", "Adam"))lr = self.hparams.get("lr", 1e-4)weight_decay = self.hparams.get("weight_decay", 1e-6)return optimizer(self.parameters(), lr=lr, weight_decay=weight_decay)def training_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x, y = batchloss = f.cross_entropy(self.forward(x), y)self.log("train_loss", loss.item())return {"loss": loss}@torch.no_grad()def validation_step(self, batch, *_) -> Dict[str, Union[Tensor, Dict]]:x, y = batchloss = f.cross_entropy(self.forward(x), y)return {"loss": loss}@torch.no_grad()def validation_epoch_end(self, outputs: List[Dict]) -> Dict:val_loss = sum(x["loss"] for x in outputs) / len(outputs)self.log("val_loss", val_loss.item()) |
可以看到,使用Pythorch Lightning可以方便的构建并训练模型。只需为训练集和测试集创建
DataLoader
对象,将其导入需要训练的模型即可。本实验中,epoch设置为25,学习率为1e-4。
|
from os import cpu_countfrom torch.utils.data import>经训练,仅通过一个非常小的模型ResNet18就取得约85%的准确率。但实际上,我们还可以做得更好!
接下来,我们使用BYOL对ResNet18模型进行预训练。在这次实验中,我选择epoch为50,学习率依然是1e-4。注:该过程是本文代码耗时最长的部分,在K80 GPU的标准Colab中大约需要45分钟。
|


本文地址: https://www.gpxz.com/article/fa863e3f6ae90fcda8fb.html



实时超声,在线超声,实时转播,会议系统

钢丝绳提升带_环形输送带_耐高温_花纹_挡边_橡胶覆盖带厂家-青岛隆源通达橡胶有限公司

南通市电站阀门有限公司始建于1960年,1975年开始批量生产全锻造电站截止阀,1979年被原国家电力部、机械部定点为电站阀门专业生产厂家,是一家专业从事各类高、中、低压电站阀门研发和制造的企业。公司现为中国通用机械工业协会阀门分会理事单位、江苏省阀门工业协会副理事长单位,是国家高新技术企业、江苏省创新型企业。

呼和浩特市人民政府办公厅主办,是呼和浩特市人民政府办公厅,以及各部门、旗县区政府在互联网上发布政府信息和提供在线服务的综合平台,第一时间权威发布呼和浩特市重大决策部署和重要政策文件,呼和浩特市领导同志重要会议、考察、出访活动等政务信息,面向社会提供与政府业务相关的服务,建设基于互联网的政府与公众互动交流新渠道。

今控环保(www.scjkhb.com)成立于2016年,业务范围:(成都,四川)污水站除臭,生物除臭设备,废气除臭处理,污水池废气除臭,污水池加盖除臭,生物除臭设备设计,制作,安装施工,检测|验收,技术托管运营,13980960188余经理,欢迎来电洽谈

新疆生产建设兵团库尔勒垦区人民法院新疆生产建设兵团库尔勒垦区法院

零点校园外卖跑腿校园总部为校园创业者的梦想助力,提供校园生活服务的各类软件应用系统,包含外卖系统,跑腿系统,校园外卖配送、校园跑腿、信息发布、自助打印、校园商城、校园新零售、宿舍超市等运营指导方案,助力打造智慧校园生活圈。

邦天物流是提倡优质服务理念的专线物流公司,宜兴物流公司以锡山物流、惠山物流、滨湖物流、梁溪物流、新吴物流、宜兴物流、宜兴物流为核心,致力于为客户提供优质高效的物流与运输服务电话18001512693

成都哪家医院治疗失眠较好,成都治疗失眠医院:成都棕南医院精神科,环境优美,交通方便,主任医师带队,一堆一面诊,收费透明,平价医院,一直以来,深受广大患者的好评 !地址:成都市二环路南二段19号。

京师堂讲师经纪是一家专门从事职业培训师发掘、推广,培训产品研发、咨询产品运营的师资机构。我们提供培训机构合作、培训师培训和企业培训师招募,致力于提高客户满意度,始终坚持“我快乐,我成功!我承诺,我做到!”的企业文化。

kintone-才望云主要从事低零代码开发平台,定制化系统软件,低零代码工具应用,crm管理系统,跟单管理系统,项目管理系统,进销存管理,售后服务管理,市场活动管理,营销活动管理,促销管理系统,协同办公管理系统、移动办公软件,销售订单管理系统软件,订单管理系统软件,客户报价管理系统软件,供应商管理系统软件,客户跟进管理系统软件,客户crm软件管理系统,合同报价管理系统软件等,才望云的企业组织数量突破多家,成为知名全球企业管理软件。

上海自动化仪表有限公司(上海自动化仪表三厂、上海自动化仪表三厂),生产销售不锈钢压力表,热电阻,热电偶,双金属温度计,电接点压力表等,产品具有广泛的适用性,在电力、石化、冶金工程中有着广泛的应用。


外媒ZDNet报道,GitHub近日承认,由于失误导致部分用户密码以明文方式暴露,GitHub是全球最大的代码托管平台,截至去年年底,GitHub拥有2700万用户,GitHub近日已经向受影响用户发送一封邮件要求他们更改密码,根据GitHub的说明,他们在执行定期审计过程中发现GitHub的一个漏洞,这个漏洞通过内部日志系统暴露少量...。

品牌是营销的重要组成部分,完成了品牌的塑造并形成一定的影响力之后,一个简单的Logo,比如说耐克旋风一样,就会成为这个品牌的强大广告,如果你常常在美国各州之间穿梭,你将会看各种描述品牌的标志符号,如麦当劳的金色拱门,goldenarches,即便是没有任何文字或图像的简单色彩组合也是可以用来作为一个品牌的,比如美国弗吉尼亚理工大学的...。

今年关于,小米不行了,的声音,此起彼伏,从五年前创立到今天,小米最大的变化,是为了平衡规模与体验之间的矛盾,在开放和封闭之间,选了第三条路——用开放的投资打造一个封闭的生态链,这是否也是让小米树敌无数的同时,成为从巅峰由盛而衰的开始?今年米粉节,在20.8亿元的销售神话中,小米生态链产品的表现可圈可点,小米智能插线板24.7万个、小米...。

一个人,无论从事什么职业,都应该有合格的职业道德,教师的职业道德,是教师为人师表应遵守的基本准则,蒙特梭利教育首先要呈现的是教师的改变,跨世纪说,老师对了,孩子就幸福了!,师德师风建设工作,一直是幼儿园的管理重点!作为园长,怎么让师德师风工作像教学工作一样有抓手,怎样把看似无形的师德师风建设工作抓出实效……经过多年来的研究探索,跨世...。

24年11月13日,骁龙8至尊版的游戏手机终于来了——红魔10Pro和红魔10Pro,正式发布,定价分别是4999元起和5999元起,这一代换成了精细度,ppi更高、边框更窄的京东方Q9,屏下前摄的真·全面屏,屏幕黑边,边框厚1.95mm,,有新的,相变液金,散热,红魔10Pro,两兄弟主要是电池和快充的分别,6.85英寸144H...。

发表在专业问答2020,8,2809,42展示机型信息,品牌型号,明基w1120部分灯泡投影仪可以查看灯泡使用时间,根据时长判断;,也可以观察灯泡内部是否出现白雾,根据白雾的大小判断光衰程度;,最直观的方法就是观察标准模式下的画面亮度情况,根据亮度明暗判断,投影仪灯泡怎么看光衰1.部分灯泡投影仪可以通过信息查看灯泡使用时间,根据时...。

乳业主要销售的产品就是牛奶,奶制品,牛奶是古老的天然饮料之一,被誉为,白色血液,,对人体的重要性可想而知,牛奶顾名思义是从雌性奶牛身上所挤出来的,在不同地区,牛奶也分有不同的等级,目前普遍的是全脂、低脂及脱脂牛奶,目前市面上牛奶的添加物也相当多,如高钙低脂牛奶,其中就增添了钙质,中国的乳业相当之多,投入加盟一定要选择适合自己的,根据,...。

据,湟中融媒,微信群众号信息,7月3日,西宁市湟中区教育局、卫生肥壮局颁布对于湟中区第一中学2名在校生因病死亡关系状况的公告,近期,湟中区第一中学有2名在校生因病死亡的信息惹起网民关注,现就关系状况公告如下,一、基本状况湟中区第一中学共有在校生4301名,其中初中生1542名,均为走读在校生;高中生2759名,其中寄宿在校生1341名...。

58同城网电话是反正这个电话难找,总是躲藏匿藏的不愿发布,有一次性我在同城上看到过,起初就再也找不到了,幸亏我记下了,58同城渣滓,系统治理老是乱删消息,58同城深圳公司的办公地址在哪里,咨询电话是多少,你好58同城深圳分公司最新地址位于,深圳市罗湖区桃园路254号HALO广场2,3楼,地图外面可以查到,电话也有,如地图所示,深圳58...。

租赁,租赁如何,什么租赁,哪些租赁,怎么租赁

网友在医院偶遇刘亦菲

8月北京租赁市场进入旺季尾声,成交规模季节性回落,租金,房源,租客,季节性,北京市,租赁市场

相信很多人对于迷宫的态度和小编一样,是那种又爱又恨的游戏,一方面想通过游戏来锻炼自己的思维,另一方面被游戏中复杂的道路和挑战难住,今天一起看充满趣味的儿童迷宫游戏,这些游戏不但孩子可以玩,大人也可以通过这些游戏找到成就感,因为游戏非常的简单,玩家在游戏中只要动脑思考就一定能找到通往成功的道路,家长可以和孩子一起玩儿这些游戏,进行趣味的...。

跟帖评论是网络上的互动形式,但也是发表一些看法的地方,昨日,国家网信办召开全国跟帖评论专项整治视频会议,部署集中治理跟帖评论存在的突出问题,各省,区、市,网信办以及部分中央新闻网站、商业网站负责人参加,腾讯表示腾讯将进一步完善跟帖评论管理机制,为网民提供高质量的跟帖评论平台,网易表示将进一步强化网站主体责任,把净化网络空间、推动网站健...。

对于创业者来说,选择是一个棘手的问题,如何选择,选择哪一个项目,都是需要慎重考虑的问题,桥头排骨小吃,在火热的餐饮项目中享有不可撼动的地位,也是众多创业者争相加盟合作的品牌商,下面就来看看,加盟桥头排骨小吃好不好,开店简单有轻松!加盟桥头排骨小吃好不好公司是一家时尚潮流的餐饮连锁品牌,打破了传统的经营模式,将经典的桥头排骨小吃制作工艺...。

人们普遍认为,人工智能曾经历过两次热潮,现在迎来了第三次热潮,1956年8月,在美国汉诺斯小镇的一所学府中,十位来自数学系、计算机系、物理系的学者和凑在一起,讨论着一个完全不食人间烟火的主题,用机器来模仿人类智能,会议足足开了两个月的时间,虽然大家没有达成普遍的共识,却为会议讨论的内容起了一个名字,人工智能,因此,1956年也就成为了...。

消息,2023年7月26日,被誉为,网络空间地图第一股,的远江盛邦,北京,网络安全科技股份有限公司,股票简称,盛邦安全,股票代码,688651.SH,正式登陆上交所科创板,共发行股份为1,888.00万股,每股发行价格为39.90元,上市首日,盛邦安全开盘价为56.66元,股,涨超42%,盛邦安全专注于网络空间安全领域,主营业务...。
