CVPR 空间 一个降低深度学习时间 经济成本的解决方案 Active 2017 Learning (cvpr空间特征增强)

雷锋网 AI 科技评论按:本文为 CVPR 2017 的论文解读,作者周纵苇(Zongwei Zhou),邮箱:zongweiz@asu.edu,微博:@MrGiovanni。本文首发于 简书 ,经作者授权,雷锋网转载。
下面要介绍的工作发表于,题为「Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally」。它主要解决了一个深度学习中的重要问题:如何使用尽可能少的标签数据来训练一个效果 promising 的分类器。根据我的判断,当遇到两种情况的时候,这篇论文的可以非常强大的指导意义:
这两个情况发生的条件是完全不同的,Situation A 发生在屌丝公司,没有钱拿到精标记的数据集,却也想做深度学习;Situation B 一般发生在高富帅公司,有海量的精标记数据,但是由于目前即使是最牛逼的计算机也不能用深度学习在短时间内一次性地去处理完这些数据(e.g.,内存溢出,或者算上个几年都算不完)。Anyway,我想我已经说清楚应用背景了,读者可以根据实际情况判断是否往后读下去。

感谢你选择继续往下阅读,那么如果觉得下文所传递的思想和方法对你有帮助,请记得一定引用这篇 CVPR 2017 的文章。 Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally.
1.为什么会想到去解决这个问题?
现在深度学习很火,做的人也越来越多,那么它的门槛可以说是很低的,Caffe,Keras,Torch 等等框架的出现,让该领域的 programming 的门槛直接拆了。所以深度学习真正的门槛变成了很简单概念——钱。这个钱有两个很重要的流向,一是计算机的运算能力(GPU Power),二是标记数据的数量。这儿就引出一个很重要的问题: 是不是训练数据集越多,深度学习的效果会越好呢? 这个答案凭空想是想不出来的,能回答的人一定是已经拥有了海量的数据,如 ImageNet,Place 等等,他们可以做一系列的实验来回答这个问题。需要呈现的结果很简单,横坐标是训练集的样本数,纵坐标是分类的 performance,如下图所示:
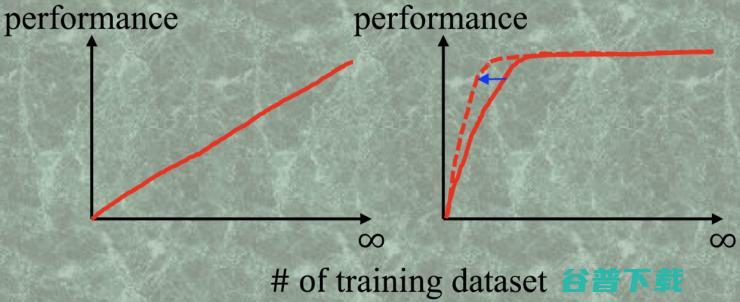
Fig.1 如果答案是左图,那么就没什么可以说的了,去想办法弄到尽可能多的训练数据集就 ok,但是现实结果是右图的红实线,一开始,训练集的样本数增加,分类器的性能快速地在上升,当训练集的样本数达到某一个临界值的时候,就基本不变了,也就是说,当达到了这个临界的数目时,再去标注数据的 ground truth 就是在浪费时间和金钱。有了这个认知,接下来就是想办法让这个临界值变小,也就是用更小的训练集来更快地达到最理想的性能,如右图的红虚线所示。红实线我们认为是在随机地增加训练集,那么红虚线就是用主动学习(Active Learning)的手段来增加训练集,从而找到一个更小的子集来达到最理想的性能。
这里需要说明的一点是,训练样本数的临界点大小和这个分类问题的难度有关,如果这个分类问题非常简单,如黑白图像分类(白色的是 1,黑色的是 0),那么这个临界值就特别小,往往几幅图就可以训练一个精度很高的分类器;如果分类问题很复杂,如判断一个肿瘤的良恶性(良性是 0,恶性是 1),那么这个临界值会很大,因为肿瘤的形状,大小,位置各异,分类器需要学习很多很多的样本,才能达到一个比较稳定的性能。
对于很多从事深度学习的无论是研究员还是企业家都是一个十分有启发性的认知改变。一般来讲,人的惯性思维会引领一个默认的思路,就是训练样本越多越好,如左图所示,这将直接导致许多工作的停滞不前,理由永远是「我们没有足够的数据,怎么训练网络!」进一步的思路是图二的红实线认知:要多少是多啊,先训着再说,慢慢的就会发现即便用自己有的一小部分数据集好像也能达到一个不错的分类性能,这个时候就遇到一个问题: 自己的数据集样本数到底有没有到达临界值呢? 这个问题也很关键,它决定了要不要继续花钱去找人标注数据了。这个问题我会在第三部分去回答它,这里先假设我们知道了它的答案, 接下来的问题就是如何让这个临界值变小?
2. 如何让临界值变小?
解决方案就是主动学习(Active Learning),去主动学习那些比较 「难的」,「信息量大的」 样本(hard mining)。关键点是每次都挑当前分类器分类效果不理想的那些样本(hard sample)给它训练,假设是训练这部分 hard sample 对于提升分类器效果最有效而快速。 问题是在不知道真正标签的情况下怎么去定义 HARD sample?或者说怎么去描述当前分类器对于不同样本的分类结果的好坏?
定义: 由于深度学习的输出是属于某一类的概率(0~1),一个很直观的方法就是用「 熵(entropy) 」来刻画信息量,把那些预测值模棱两可的样本挑出来,对于二分类问题,就是预测值越靠近 0.5,它们的信息量越大。还有一个比较直观的方法是用「 多样性(diversity) 」来刻画 labeled target="_blank">「Active batch selection via convex relaxations with guaranteed solution bounds」中被提出。是十分重要的两个 Active Learning 的选择指标。
有了这两个指标来选 hard sample,是比较靠谱了——实验结果表明,这比随机去选已经能更快地达到临界拐点了。
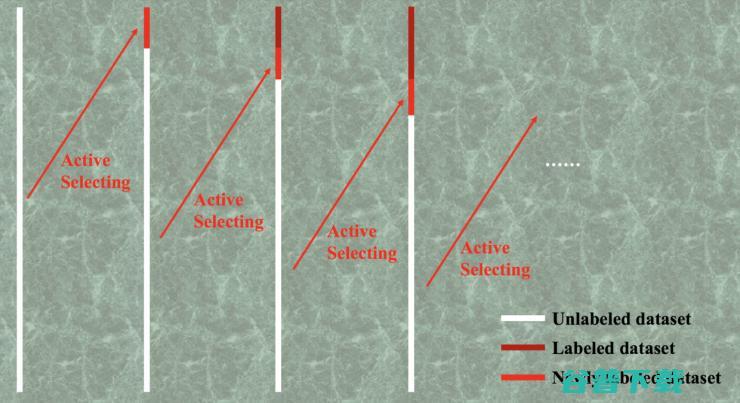
Active Learning 的结构示意图。利用深度学习所带来的优势在于,一开始你可以不需要有标记的数据集。
举例来讲,假设你是一个养狗的大户,你现在想做一个非常偏的(专业化的)分类问题,如 卷毛比雄犬 和 哈瓦那犬 的分类问题,你手头有这两种狗各 50 条,你自己可以很轻松地区分这 100 条狗,现在需要做的是训练一个分类器,给那些不懂狗的人,他们拍了狗的照片然后把照片输入到这个分类器就可以很好地判断这是卷毛比雄犬还是哈瓦那犬。首先你可以给这 100 条狗拍照片,每条狗都有不同形态的 10 张照片,一共拍了 1000 张没有标记的照片。对于这 1000 张照片,你所知道的是哪 10 张对应的是一条狗,其他什么都不知道。
在这个实际分类问题中,你拥有绝对的数据优势,即便是 Google Image 也不能企及,当然一种选择是你把 1000 张图片从头到尾看一遍,标注好,但是你更希望是把大多数简单的分类工作交给分类器,自己尽可能少的做标记工作,并且主要是去标记那些分类器模棱两可的那几张照片来提高分类器的性能。
我们初步提供的解决方案是 (参考或者):
如所示,每次循环都用不断增加的标记数据集去提升分类器的性能,每次都挑对当前分类器比较难的样本来人为标记。
3. 这个过程什么时候可以停?
以上三种情况都可以让这个循环训练过程中断,第一种就很无奈了,没钱找人标记了... 第二种情况和第三种情况的前提共识是如果难的样本都分类正确了,那么我们认为简单的样本肯定也基本上分类正确了,即便不知道标签。第三种情况,举例来说就是黑白图像分类,结果分类器模棱两可的图像是灰的... 也就是说事实上的确分不了,并且当前的分类器居然能把分不了的样本也找出来,这时我们认为这个分类器的性能已经不错的了,所以循环训练结束。
至此,主要讲了传统的 Active Learning 的思想,接下来会讲讲这篇 CVPR2017 论文的几个工作点。
上面我讲到了 Active Learning 的大概思路,如所示,是一个很有意思的概念,说实话很实用,我在 Mayo Clinic 实习的时候,每次遇到新的数据集,都会想着用一用这个方法,来让给数据标注的专家轻松一点...
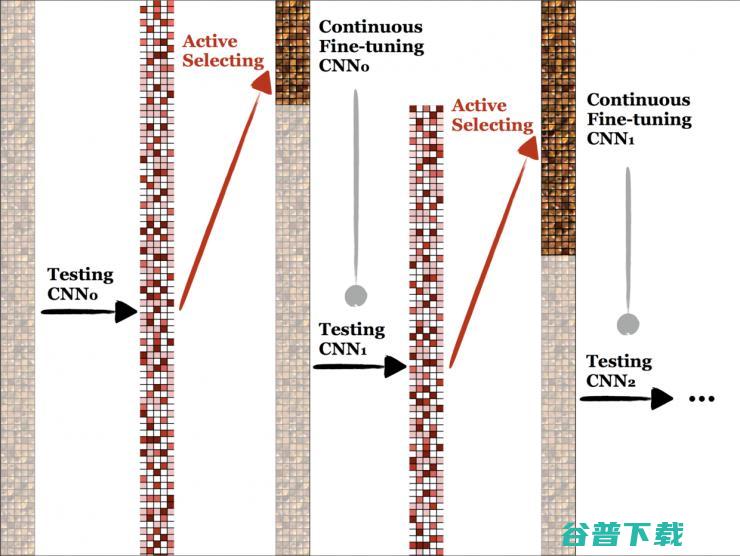
Fig.3 暗的表示 unlabeled 的数据,高亮的表示 labeled 的数据,CNN 的结构可以随便挑 SOTA 的无所谓,CNN0 是拍 retrained from ImageNet,得到的第二列表示每个 image 对应的 importance 指标,越红的说明 entropy 越大,或者 diversity 越大,每次挑这些 important 的 sample 给专家标注,这样 labeled 的数据就变多了,用 labeled 的数据训练 CNN,得到新的更强的分类器了,再在 unlabeled target="_blank">Active batch selection via convex relaxations with guaranteed solution bounds」的描述,Diversity 是计算 labeled>
这样的 diversity 就完美了吗?并没有... 读者可以先猜猜哪儿又出问题啦,我在第五部分会指出来。

5. 这次是 target="_blank">Augmentation Lecture讲到的平移 crop,如果我们将它应用到猫的分类问题中,很有可能得到这样的训练样本:

Fig.4 左图是原始的图像,中间的 9 个 patches 是根据平移变化的扩充得到的,restrictions: region must contain objects or part of the object 详见这里,右图是网络得到的对应 patch 的预测值。
可以看出,在这个实例中,对于一个 candidate,网络预测的一致性很低,套用 Diversity 的公式,Diversity 的值很大,也就是说,应该被认为是 hard sample 挑出来。但是仔细观察一下这九个 patches 就不难看出,即便是很好的分类器,对于中间图中的 1,2,3,也是很难分出这个是猫... could be rat, rabbit, etc. 我们把像这三个 patch 的例子叫做从>

至此,主要讲了这篇论文是怎样成功的将 Diversity 这个重要的指标引入到 Active Learning 中来,所有的 Active Selection 部分结束。
6. 如何训练?
既然用了迁移学习,那么一开始的 CNN 测试的效果肯定是一团糟,因为这个 CNN 是从自然图像中学过来的,没有学习过 CT 这种医学影像,所以这个 loop 的启动阶段,Active Learning 的效果会没有 random selecting 好。不过很快,随着 CNN 慢慢地在 labeled 的 CT 上训练,Active Learning 的效果会一下子超过 random selecting。
接下来讨论 Continuous fine-tuning 的细节,随着 labeled target="_blank">here.
Find poster.
Find author.
祝好,

版权文章,未经授权禁止转载。详情见 转载须知 。

本文地址: http://www.gpxz.com/article/02db31446b6454370909.html


平邑石材网,石材批发网,石材加工厂,异形石材加工,异型石材加工厂,石材厂家,大理石批发网,大理石加工厂家,大理石厂家,石材加工厂,石材图片大全,大理石批发,大理石加工厂,异形石材批发,异型石材加工,有外墙干挂批发,地铺石批发,异形石材批发,用于:庭院装饰石材,园林景观石材等,联系电话:18053977799

上海枞富建筑装潢设计有限公司是一家集设计、装饰、施工于一体的装饰公司,以现代市场观念为全新经营理念的专业装饰公司.

x8销售管理系统是集商品销售管理与会员管理为一体的综合管理系统,拥有专业的技术研发人员,为您提供高品质的商店会员、商品管理解决方案;支持多店连锁管理,使x8更适用于具有多家连锁店的商家使用;

海河网是一个多元化的综合性网站,为您提供丰富多彩的旅游、新闻知识内容。我们致力于为广大用户提供全面、及时、可靠的信息,满足不同需求的阅读和学习。

文康物流是一家专业的义乌物流公司,义乌货运专线,义乌搬家物流,提倡优质服务理念的专线物流公司,服务电话18072359751。

软告营销云平台针对不同客户提供定制化SaaS服务。用大数据和云端系统整合了TD、DAP、DSP、DMP、SSP五个产品,营销云将大幅提升营销产业链的效率并将革新营销产业链,营销云为广告主提供基于SaaS的营销解决方案、互联网广告的精准效果投放以及为互联网媒体提供基于SaaS的系统解决方案。

广州泰琦广告设计有限公司专注展览设计搭建,为企业提供展台设计_展台搭建_快闪店装修_美陈设计装修_进博会展台装修等一站式设计施工服务。咨询热线:13719402973

A8软件站是专业安全的软件免费下载网站,每天为大家整理最新的安卓软件和安卓游戏,保证无病毒和木马插件,请大家放心使用

菜谱街是一个集菜谱大全、家常菜、做菜窍门、美食做法、食物功效等信息于一体的网站。在菜谱街网上,你可以找到各种丰富多样的菜谱,包括家常菜、地方特色菜、美食做法、节日美食等,满足不同人的口味需求。此外,网站还提供了许多做菜的窍门和技巧,帮助你更好地掌握厨艺,做出美味又营养的菜肴。

磐石温泉网是一个专门提供温泉相关信息的网站,包括温泉百科、温泉酒店、温泉度假村、温泉旅游、温泉疗养等内容。在磐石温泉网上,可以了解到各种温泉的功效、泡温泉的注意事项、温泉度假村的推荐等信息,帮助人们更好地享受温泉疗养的乐趣。

桂林腻子粉厂家:广西桂林市刚玉建材有限公司位于广西桂林市秀峰区矮山塘亚太工业园对面,是集研发、生产、销售于一体的高科技建筑材料制造企业。公司会聚了丰富经验的技术人才及高素质的管理队伍,引进了先进国家三十多年的生产经验及先进水平的核心原材料,结合国内气候及国家标准、规范,生产各类性能优越的内外墙水性腻子粉、防水涂料、填缝剂、瓷砖胶、保温材料等系列建材产品。

济宁公积金管理中心,统一服务电话:12345,可查询业务包括:公积金贷款利率,通知公告,业务指南,新闻动态,服务渠道,网上贷款利率,主任信箱,客服电话,网点查询,党建工作,在线留言,合作楼盘,下载中心,政府信息公开等。


野外求生游戏有哪些介绍,这些游戏不仅提供了丰富的生存机制,还通过独特的游戏设定和故事背景,让玩家在紧张刺激的求生过程中感受到无尽的乐趣,无论你是生存游戏的老手还是新手,这些游戏都能让你在这其中找到属于自己的生存之道,1、,生存岛野外逃生,野生动物的出没更是增加了游戏的难度,每种动物都有其独特的攻击方式和威胁,玩家必须时刻保持警惕,在这...。

goodnotes怎样设置中文,goodnotes新打开的时候界面显示的是英文的界面,很多的用户使用非常的不方便,其实是可以更换成中文的,那么应该怎么设置呢,还不清楚的用户就一起来看看吧!...。

雷锋网AI科技评论按,距离8·12天津滨海新区爆炸事故已经过去了两周年,这起因危险品的不合理存放和管理导致的重大伤亡事故也让高校科研人员高度关注如何用大数据来防患于未然,如何寻找这些存在潜在威胁的区域,又如何能规避危险的发生,北京航空航天大学计算机学院和经管学院的合作团队研发了一个名为DangerousGoodsEyes,DGeye,...。

最近,WireLurker,病毒可谓名噪一时,它不仅攻陷了曾经,金刚不坏,的iOS系统,还让国内安全厂商360也深感忧愁,为何如此,还要从,WireLurker,病毒的传播站点麦芽地说起,麦芽地是一家Mac应用分享和讨论论坛,类似iOS之于威锋网论坛,360是麦芽地的早期天使,在其,起飞计划,内投资了麦芽地50万元人民币占股25%,因...。

现在人们的生活条件已经得到了很大的改善,对于家庭式的生活品质追求也会越来越高,比如说家居行业就是不能够忽视的一个行业,有关这一行业也开始了一个新的发展,有关家居的需求量也是越来越多了,那么对于家居加盟店排行榜,想要创业的朋友们是一定要关注的,挑选一个能够上榜的品牌进行加盟,才能够获得总公司的更多关注,该品牌是隶属于山东巧夺天工家具有限...。
北京时间8月20日,声网母公司Agora,Inc.,NASDAQ,API,发布了2024年第二季度财报,财报显示,本季度Agora,Inc.实现总营收3420万美元,同比增长0.5%,这也是在2021年Q4之后,10个季度以来Agora,Inc.首次实现营收同比增长,其中,业务聚焦在中国市场的声网实现Q2营收1.32亿人民币,同比增长...。

之前在汉口常青路,有个常青化工市场,全都是卖化工用品的,后来搬到了盘龙城,296路公交车可以直接到,但是要跟司机大哥打个招呼,到了地点他会叫你,因为是搬迁不久所以,比较少有人知道,武汉哪有化学用品店1、茂源化工用品市场,武汉市天阳区木三路63号,2、海阳化工用品市场,武汉市白凯区核桃路328号,3、天门化工用品市场,武汉市林木区飞霞路...。

央视网信息,海关总署11月12日再次出台推进西部陆海新通道树立15条重点动作,关键聚焦继续优化跨境班列全体运转效率;扩展铁海联运境内段运费扣减政策范畴等,允许打造内陆开明综合枢纽,进一步推进西部陆海新通道高品质开展,前10月通道进进口1.15万亿元同比增8.8%2024年是,西部陆海新通道总体布局,印发五周年,2024年1至10月,全...。

关于为什么雪铁龙毕加索二手车多少钱相对较低的疑问,有几个要素可以解释,首先,法系车在国际的品牌出名度相对较低,而且保有量也较少,这或许造成培修爱护方面的疑问,其次,毕加索的外观设计过于超前,不合乎国际群众的审好看念,此外,这款车的定位是单厢车,而国际消费者广泛以为只要三厢车才是轿车,因此对单厢车的需求较低,另外,毕加索的一些设计特点也...。

据河津融媒信息,7月3日,山西河津警方颁布悬赏公告,2日,一辆车牌为陕A00N58彩色路虎途经酒醉驾卡点时,不配合酒精检测,冲撞执勤警车后逃逸,公告全文如下,司机为何见查酒驾弃车而逃,近日,司机见查酒驾弃车而逃原来涉嫌强奸8月18日讯近日,在晋城市泽州县交警一次夜查酒驾行动中,一男子见势不妙直接弃车而逃,交警在随后调查中发现,这名男子...。

茶苑游戏大厅是一款以地方性棋牌为主的游戏平台,像温州、常州、商都、丽水、金陵等地方的特色棋牌都可以在大厅中找到,当然,还有很多其他大众化的棋牌游戏,赶快下载体验吧!游戏茶苑大厅官网介绍游戏茶苑大厅拥有美观、舒适的外观,从温州出发,以经典双扣系列为

微信多开器支持个人多开及企业微信多开,微信电脑版的用户都会发现一个不友好的事情,那就是微信PC版不支持多开,也就是不能同时登陆多个账号,这对于需要在电脑上登陆多个微信账号的朋友来说肯定是极其的不方便。而这款微信多开器就支持多开,并且支持个人多开及企业微信多开。软件原理关闭微信单实例互斥体,无Hook,不修改任何文件,支持当前最新版本

本期小编要给大家带来的是2023值得一试的自由建造与生存的游戏有哪些,有一种类型的游戏,看起来很枯燥,但其实很有趣,因为他们的自由度很高,为了让这款游戏变得更加有趣,它还加入了求生的元素,这一点从这款游戏的下载数量就能看出来,这就需要玩家拥有强大的思考能力,来构建属于自己的世界,同时,还要想办法活下去,更适合那些不想被游戏规则所约束,...。

很多小伙伴都有自己创造音乐的念头,但之前由于智能手机的技术还不是很完善,所以没有什么软件能够完成这一理想,而如今科学技术发展的壮大,让智能手机的功能也越来月强大了,接下来介绍自己制作音乐的软件有哪些,找到自己喜欢的那一个音乐制作软件去下载体验,相信在大家的努力之下能够制作出非常动听优美的旋律,1、,5sing原创音乐,比较大的原创音乐...。

软件开发领域的DevOps理念正在加速国产化芯片的研发进程,芯片国产化浪潮下,芯片设计研发的效率提升逐渐成为行业关注的重要议题,随着敏捷开发概念的提出,国内芯片设计行业在EDA工具的智能化和国产化进程上开始提速,借助一站式DevOps方案,腾讯云在提升国产芯片研发效率上已经走在了行业前列,有效解决开发环境搭建难题芯片研发的第一步是开发...。

发表在专业问答2022,9,1616,06展示机型信息,品牌型号,索尼电视X80J、PS4国行版系统版本,当贝OS定制版、Linuxps4连接sony电视需要通过HDMI线进行连接,总共可以分为三步,下面为ps4怎么连接sony电视的详细步骤做具体说明,ps4怎么连接sony电视1、连接电视和PS4使用HDMI线连接sony电视和PS...。

发表在峰米投影仪2024,9,1817,23峰米激光电视T2是峰米最新的超短焦激光投影产品,拥有出色的画质和强大的性能,具体峰米激光电视T2怎么样呢,下面就分享峰米激光电视T2的详细参数配置,看看峰米激光电视T2各方面优缺点有哪些,是否符合家用,峰米激光电视T2怎么样,1.光学参数峰米激光电视T2采用的是ALPD全色激光技术,可提供鲜...。
