大数据背景下的最佳异常检测算法 孤立森林 (大数据背景下财务会计的转型与发展)
双语原文链接: Isolation Forest is the best Anomaly Detection Algorithm for Big>"iForest" 是一个优美动人,简洁优雅的,只需少量参数就可以检测出异常点。原始论文中只包含了最基本的数学,因而对于广大群众而言是通俗易懂的。在这篇文章中,我会总结这个算法,以及其历史,并分享我实现的代码来解释为什么是现在针对而言最好的异常检测算法。
为什么iForest是现在处理大数据最好的异常检测算法
总结来说,它在同类算法中有最好的表现。在多种数据集上的表现和精确度都比大多数其他的异常检测算法要好。我从的作者们那里取得了基准数据,并在中逐行使用绿红梯度的条件格式化。用深绿色来标识那些在这个数据集上有最好的表现的算法,并用深红色来标识那些表现得最差的:

绿色表示好而红色表示差。我们看到在很多的数据集以及总体的角度上是领先的,正如平均值,中位数,标准差的颜色所表示。图源:作者。数据源:
我们看到在很多的数据集上以及总体上的表现是领先的,正如我计算出来的平均值,中位数,标准差的颜色所表示的一样。从(最重要的项指标的准确度)的表现来看也能得出同样的优秀结果。
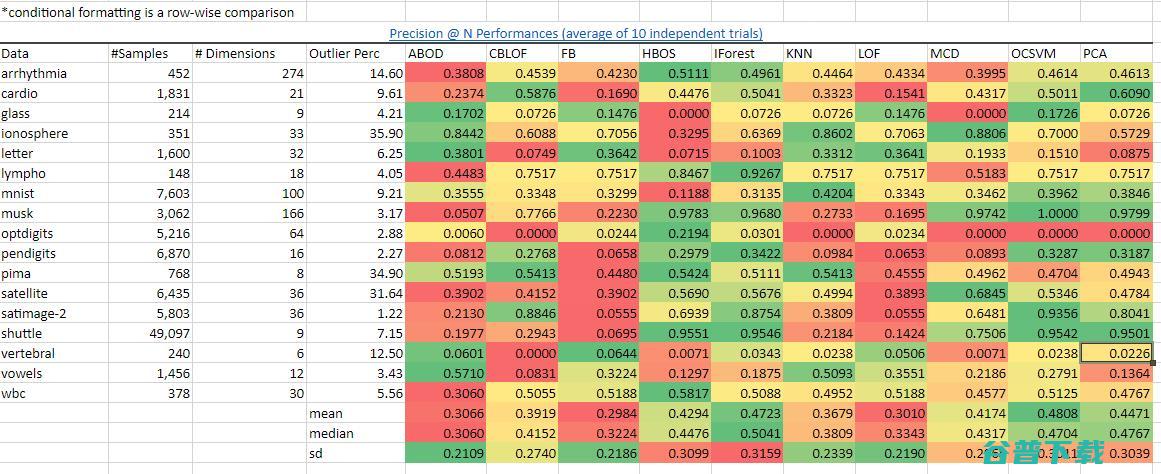
图源:author.Data
源:
可扩展性。以它表现出来的性能为标准而言是最快的。可以预料到的是,和基于频数直方图的异常点检测算法()在所有的数据集上都有更快的速度。
近邻算法()则要慢得多并且随着数据量变多它会变得越来越慢。
我已经成功地在一个包含一亿个样本和三十六个特征的数据集上构建出孤立森林,在一个集群环境中这需要几分钟。而这是我认为的算法没办法做到的。
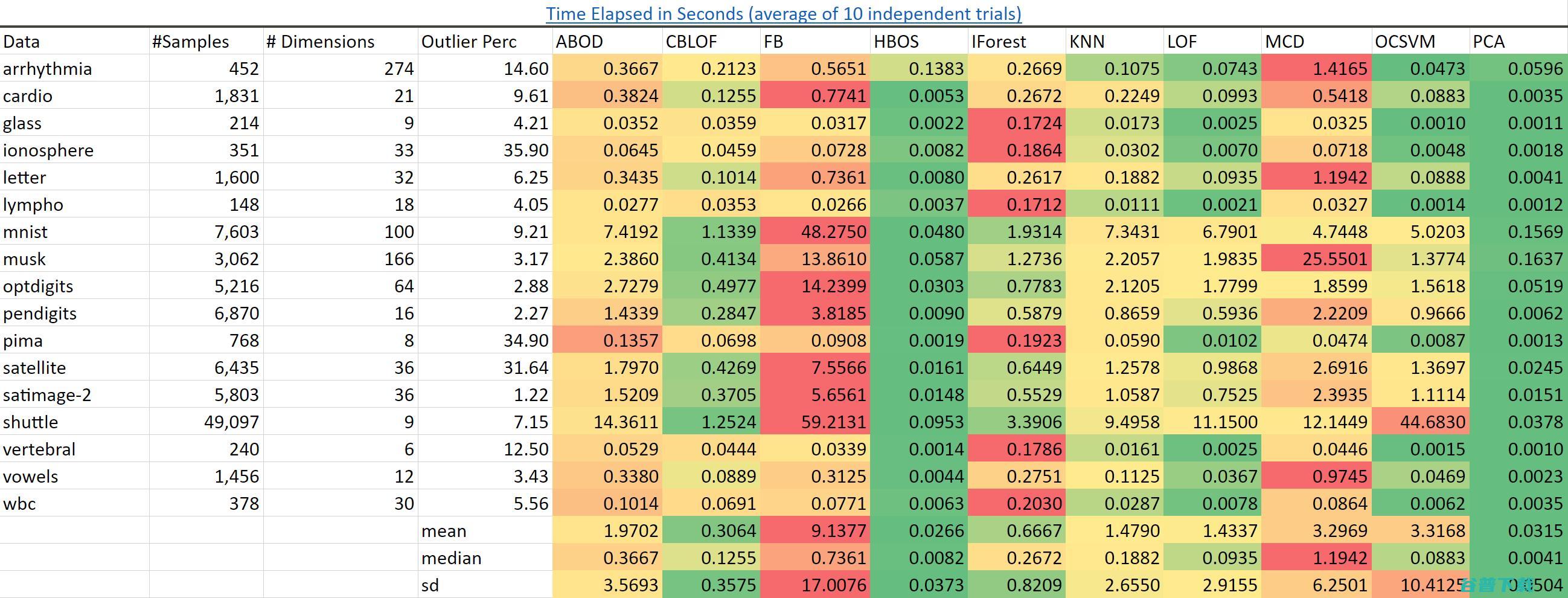
图源:author.Data
源:
要点/总结
我通过下面的综述来非常简洁地总结原来有10页内容的论文:
孤立树节点的定义:T或是一个没有子节点的叶子节点,或者是一个经过检验的内部节点,并拥有两个子节点(Tl,Tr)。我们通过递归地进行下述过程来构造一棵iTree:随机选择一项特征q和一个分割值p来划分X,直到发生下列情形之一为止:(i)树到达了限制的高度,(ii)所有样本被孤立成一个只有他们自己的外部节点,或者(iii)所有数据的所有特征都有相同的值。
路径长度:一个样本x的路径长度h(x)指的是从iTree的根节点走到叶子节点所经历的边的数量。E(h(x))是一组孤立树的h(x)的平均值。从这个路径长度的平均值,我们可以通过公式E(h(x)):s(x,n)= 2^[^[− E(h(x)) / c(n)]来得到一个异常分数s(x,n)。基本上,s和E(h(x))之间存在一个单调的关系。(想知道细节的话请查阅文末的附录,有一张图描述了他们之间的关系)。这里我不会讨论c(n),因为对于任意给定的静态数据集而言它是一个常数。
用户只需要设置两个变量:孤立树的数量和训练单棵树的子采样大小。作者通过对用高斯分布生成的数据做实验来展示了只需要少量的几棵树和少量的子采样数量就可以使平均路径长度很快地收敛。
小的子采样数量(抽样的抽样)解决了和问题。造成这两个问题的原因是输入的数据量对于异常检测这个问题来说太大了。是指由于某个正常的样本点被异常点所包围而被错误地标注为异常,则是相反的情况。也就是说,如果构建一个树的样本中有很多异常点,一个正常的数据点反而会看起来很异常。作者使用乳房线照相的数据来作为这个现象的一个例子。
小的子采样数量使得每一棵孤立树都具有独特性,因为每一次子采样都包含一组不同的异常点或者甚至没有异常点。
不依赖距离或者密度的测量来识别异常点,因此它计算成本低廉且有较快的速度。这引出了下一个议题。
线性的时间复杂度,()。不正规地说,这意味着运行时间随着输入大小的增加最多只会线性增加。这是一个非常好的性质:
历程
见多识广的读者应该知道一个优秀的新想法出现与它的广泛应用之间可能会有数十年之久的间隔。例如,逻辑函数在年被发现,在年被重新发现(更多信息可参考)而到如今才被数据科学家频繁地用于逻辑回归。在最近几十年,一个新想法和它被广泛应用的间隔时间已经变得更短了,但这仍然需要一段相对较为漫长的时间。最先在年公开,但直到年后期才出现了可行的商业应用。 这是其时间线:
12/2008 -iForest的原始论文发布(论文)
07/2009 -iForest的作者们最后一次修改其代码实现(代码)
10/2018 -h2o小组实现了版和R版的iForest(代码)
01/2019 -PyOD在Python上发布了异常检测工具包(代码,论文)
08/2019 -Linkedln 工程小组发布了 iForest的Spark/Scala版本实现(代码,通讯稿)
代码实现
由于这篇文章是关于的,我采用了的集群环境。这里省略的大部分的脚手架(软件质量保证和测试之类的代码)的代码。如果在配置集群环境中需要帮助,可以参考我的文章:如何为搭建高效的
集群和
我发现能很轻易且快捷地处理万行,个特征的数据,只需几分钟就完成计算。
| importh2o#h2oautoMateddatacleaningwellformydatasetimportpkg_resources###################################################################printpackages+versionsfordebugging/futurereproducibility###################################################################dists=[dfordinpkg_resources.working_set]#Filteroutdistributionsyoudon'tcareaboutanduse.dists.reverse()dists###################################################################initializeh2oclusterandloaddata##################################################################h2o.init()#importpyarrow.parquetaspq#allowloadingofparquetfilesimports3fs#forworkinginAWSs3s3=s3fs.S3FileSystem()df=pq.ParquetDataset('s3a://datascience-us-east-1/anyoung/2_processedData/stack_parquetFiles',filesystem=s3).read_pandas().to_pandas()#checkinputdataloadedcorrectly;prettyprint.shapeprint('('+';'.join(map('{:,.0f}'.format,df.shape))+')')#ifyouneedtosampledatadf_samp_5M=df.sample(n=5000000,frac=None,replace=False,weights=None,random_state=123,axis=None)#convertPandasDataFrameobjecttoh2oDataFrameobjecthf=h2o.H2OFrame(df)#dropprimarykeycolumnhf=hf.drop('referenceID',axis=1)#referenceIDcauseserrorsinsubsequentcode#youcanomitrowswithnasforafirstpasshf_clean=hf.na_omit()#prettyprint.shapewiththousandscommaseparatorprint('('+';'.join(map('{:,.0f}'.format,hf.shape))+')')fromh2o.estimatorsimportH2OIsolationForestEstimatorfromh2o.estimatorsimportH2OIsolationForestEstimatorfullX=['v1','v2','v3']#splith2oDataFrameinto80/20train/testtrain_hf,valid_hf=hf.split_frame(ratios=[.8],seed=123)#specifyiForestestimatormodelsisolation_model_fullX=H2OIsolationForestEstimator(model_id="isolation_forest_fullX.hex",seed=123)isolation_model_fullX_cv=H2OIsolationForestEstimator(model_id="isolation_forest_fullX_cv.hex",seed=123)#trainiForestmodelsisolation_model_fullX.train(training_frame=hf,x=fullX)isolation_model_fullX_cv.train(training_frame=train_hf,x=fullX)#savemodels(haven'tfiguredouthowtoloadfroms3w/opermissionissuesyet)modELFile=isolation_model_fullX.download_mojo(path="~/",get_genmodel_jar=True)print("Modelsavedto"+modelfile)#predictmodelspredictions_fullX=isolation_model_fullX.predict(hf)#visualizeresultspredictions_fullX["mean_length"].hist() |
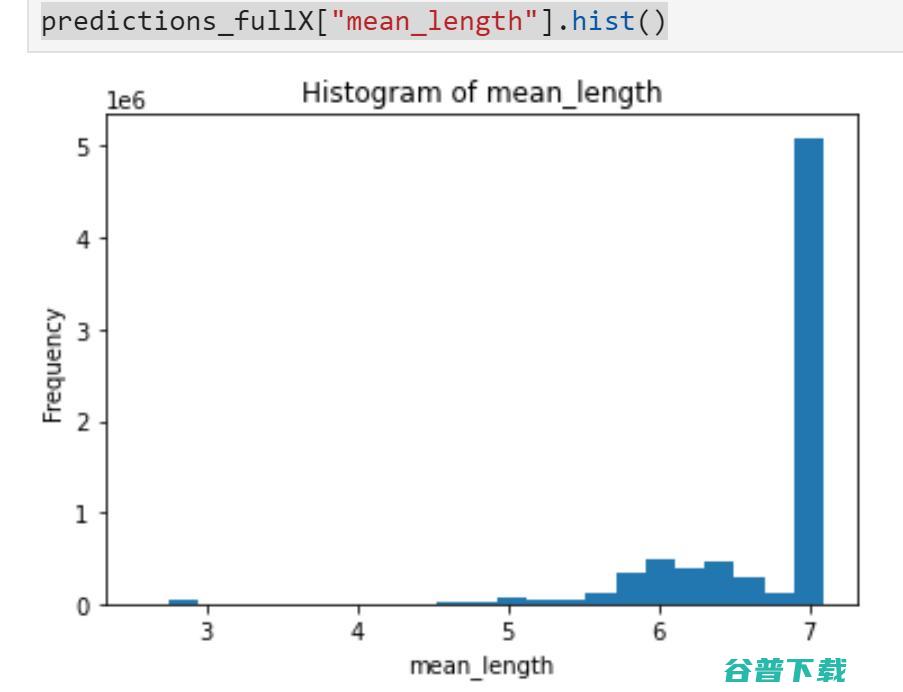
如果你使用来验证你的带标签数据,你可以通过比较数据集中的正常数据的分布,异常数据的分布,以及原来数据集的分布来进行进一步推理。例如,你可以查看原本数据集中不同的特征组合,像这样:
| N=df.count()df[['v1','v2','id']].groupby(['v1','v2']).count()/Ndf[['v1','v3','id']].groupby(['v1','v3']).count()/N... |
并与使用得出的正常异常数据集进行比较。正如下面所展示的这样:
| ###################################################################columnbindpredictionsfromiForesttotheoriginalh2oDataFrame##################################################################hf_X_y_fullX=hf.cbind(predictions_fullX)###################################################################Sliceusingabooleanmask.Theoutputdatasetwillincluderows#withcolumnvaluemeetingcondition##################################################################mask=hf_X_y_fullX["label"]==0hf_X_y_fullX_0=hf_X_y_fullX[mask,:]mask=hf_X_y_fullX["label"]==1hf_X_y_fullX_1=hf_X_y_fullX[mask,:]###################################################################Filtertoonlyincluderecordsthatareclearlynormal##################################################################hf_X_y_fullX_ml7=hf_X_y_fullX[hf_X_y_fullX['mean_length']>=7]hf_X_y_fullX_0_ml7=hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length']>=7]hf_X_y_fullX_1_ml7=hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length']>=7]###################################################################ConverttoPandasDataFrameforeasiercounting/familiarity##################################################################hf_X_y_fullX_ml7_df=h2o.as_list(hf_X_y_fullX_ml7,use_pandas=True)hf_X_y_fullX_0_ml7_df=h2o.as_list(hf_X_y_fullX_0_ml7,use_pandas=True)hf_X_y_fullX_1_ml7_df=h2o.as_list(hf_X_y_fullX_1_ml7,use_pandas=True)###################################################################Lookatcountsbycombinationsofvariablelevelsforinference##################################################################hf_X_y_fullX_ml7_df[['v1','v2','id']].groupby(['v1','v2']).count()hf_X_y_fullX_0_ml7_df=h2o.as_list(hf_X_y_fullX_0_ml7,use_pandas=True)...#Repeataboveforanomalousrecords:###################################################################Filtertoonlyincluderecordsthatareclearlyanomalous##################################################################hf_X_y_fullX_ml3=hf_X_y_fullX[hf_X_y_fullX['mean_length']<3]hf_X_y_fullX_0_ml3=hf_X_y_fullX_1[hf_X_y_fullX_0['mean_length']<3]hf_X_y_fullX_1_ml3=hf_X_y_fullX_3[hf_X_y_fullX_1['mean_length']<3]###################################################################ConverttoPandasDataFrameforeasiercounting/familiarity##################################################################hf_X_y_fullX_ml3_df=h2o.as_list(hf_X_y_fullX_ml3,use_pandas=True)hf_X_y_fullX_0_ml3_df=h2o.as_list(hf_X_y_fullX_0_ml3,use_pandas=True)hf_X_y_fullX_1_ml3_df=h2o.as_list(hf_X_y_fullX_1_ml3,use_pandas=True) |
我完整地实现了上面的代码并把我的数据输出到中,很快就可以得到如下的一些累积分布函数:
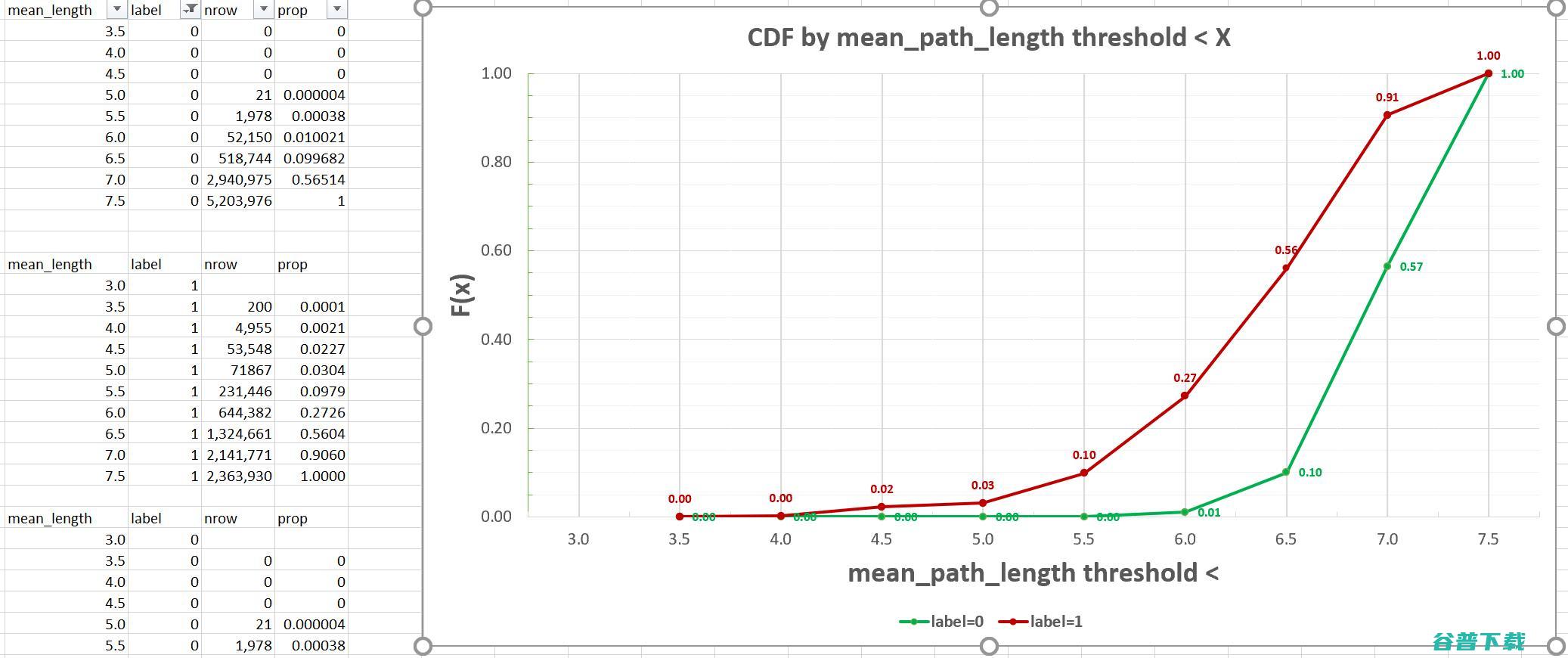
图源:作者自己的作品。绿线表示标识为的数据,即正常样本红线
代表的是标识为的样本,被认为有可能是异常的。
参考文献
AI研习社是AI学术青年和AI开发者技术交流的在线社区。我们与高校、学术机构和产业界合作,通过提供学习、实战和求职服务,为AI学术青年和开发者的交流互助和职业发展打造一站式平台,致力成为中国最大的科技创新人才聚集地。
如果,你也是位热爱分享的AI爱好者。欢迎与译站一起,学习新知,分享成长。

版权文章,未经授权禁止转载。详情见 转载须知 。

本文地址: https://www.gpxz.com/article/a425dc76926f0446d6f0.html



hao123房产栏目为您提供租房买房网站、装修网址、房产行业以及本地房产网站查找服务。

上海楠傲网络科技有限公司www.jnljm.com经营范围含:家居用品、来电显示器、轿车、熏香、工程承包、室外照明灯、灯具、户外服装、旅游休闲旅游用品、商务服务(依法须经批准的项目,经相关部门批准后方可开展经营活动)。

4399红白机小游戏大全收录国内外红白机类小游戏,包括红白机闯关小游戏,红白机冒险小游戏等。游戏虽好,也不要忽视身边的人哦,拉他们一起来!

搜轴承网拥有最完整的轴承新旧型号对照、轴承型号尺寸查询,轴承价格在线查询!轴承型号查询,上搜轴承网

爱喊话分类信息网商家中心为您提供房产、招聘、黄页、团购、交友、二手物品、宠物、车辆、周边游等海量分类信息,充分满足您免费查看和发布信息的需求。爱喊话分类信息网,免费高效的分类信息平台。

厦门小鱼网

厦门易瑞通是百度开户指定的代理商,主营百度营销推广开户、信息流、爱采购、知了好学、装馨家、百度品牌推广以及自营的智能建站、小程序、基木鱼、域名注册等服务。按效果收费让网络推广更靠谱,专业的品牌营销策划让企业的宣传性价比更高。

鑫浪科技主要致力于数码防伪技术和企业数字化管理软件的销售和服务,主营产品有一物一码,防伪标签,防伪码,防窜货系统,二维码营销,微商管理系统等产品。在食品、医药、保健品、婴童产品、烟酒、日化、快消品、电子电器、IT、图书、农资、养殖业等众多行业深得客户的青睐与信任,为产品的质量安全提供完美服务和保障。

重庆沃克斯科技股份有限公司专业从事蓄热式高精度工业炉,节能低氮工业炉的开发、研究和制造的中国高新技术企业.沃克斯蓄热式工业炉具有操作简单、工作稳定、极低的使用和维护维修成本和超长使用寿命等特点.欢迎新老顾客来电咨询!

宇杰科技

好软下载网,致力于为移动端手机用户提供免费好用的安卓、苹果手机游戏与应用软件下载,海量热门游戏,精品冷门小众作品随时下载体验,还包含最新游戏资讯,游戏行业新动态,软件教程,游戏软件排行榜前十名,热门游戏标签合集等内容。

西安金雕机械模型设计有限公司成立于2010年8月,是一家专业专业设计制作国内外、科技、地产、军事、机械、车、船、工业、能源化工、工程机械、航空航天、石油设备、煤炭、水利电力、教学、馆藏等多媒体声、光、电、动态展览模型,科技馆、展览馆藏品质等教学模型。


学英语口语的最好的app你知道吗,随着现在社会的不断发展,英语已经成为了人们必要掌握的一项语言能力,在我们的工作和学习当中能够提供很大的帮助,只是平时有的小伙伴们上学的时候可能学习成绩并不是太好,后期在工作当中需要学习一些英语口语的应用,那么可以通过一些学习口语的app来提升自己的能力,下面小编给大家整理了学英语口语好的app推荐,有...。

随着饮食行业的茁壮发展,许许多多的创业人纷纷以加盟的方式开启了创业之旅,其中有许多人的眼光就投入到华客多汉堡的加盟中去,实际上像汉堡这种制作起来简单快捷的食品是非常受大家追捧的,越来越多的人选择加盟过去的原因还包括加盟后加盟商们所得到的总部支持是非常强有力的,那么,华客多汉堡加盟费是多少,一、华客多汉堡加盟费是多少,华客多汉堡加盟费大...。

发表在当贝投影仪2024,4,1819,45当贝X5S是最新上市的激光投影设备,拥有出色的性能配置,采用最新的旗舰芯片,那么当贝X5S和同为旗舰产品的极米H6有什么区别呢,下面就通过详细的参数配置进行对比分析,看看当贝X5S和极米H6有什么区别,哪款更值得入手,一、当贝X5S和极米H6有什么区别,1.光学参数对比在光源方面,当贝X5S...。

申明,1.以上内容仅代表揭发者自己,不代表黑猫揭发立场,2.未经授权,本平台案例制止任何转载,违者将被清查法律责任,3.黑猫揭发处置揭发不收取任何费用,凡以黑猫揭发名义不要钱的均为混充、诈骗行为,请及时报警并与黑猫官网反应,揭发邮箱heimaotousu@vip.sina.com,4.请大家选用官网渠道处置生产纠纷,不要轻信第三方机构...。

7月15日,北京大兴机场警方通报一同,外籍女子躲客机厕所吸电子烟引发机组恐慌,关系案例,目前,该女子已被处分,据引见,2024年6月14日早晨,一架由舟山飞往北京大兴的航班正在万米空中朝着既定方向颠簸航行,突然烟雾报警器响起,机组人员为了不惹起旅客恐慌,立刻依照处理预案头头是道展开排查上班,经排查发现,一名外籍旅客正在客舱后部卫生间内...。

1、梦见梦很多芝麻的吉凶指数基础运吉而能达有限之成就,但因成功运遭到压抑,故成功之后便难再舒展了,宜养,仁德雅量,,可逃灾祸而得安康,中吉,吉凶指数,76,仅供参考,2、梦见梦很多芝麻的宜忌,宜,宜慢跑,宜做鬼脸,宜购物,忌,忌注销结婚,忌封锁好友圈一天,忌施舍,3、梦见梦很多芝麻的预兆恋爱中的人梦见梦很多芝麻,说明被蒙在鼓里,将...。

[全球网报道]综合路透社、塔斯社等多家媒体7月2日报道,依据美国商务部下属机构工业和安保局颁布的信息,该部门选择把6家来自中国、南非、阿联酋以及英国的实体列入无关,实体清单,,要素与所谓,国度安保,和外交政策疑问无关,据路透社报道,上述6家实体中,来自中国和阿联酋的实体各有两家,来自南非和英国的实体各有1家,报道称,美方选择对这些实体...。

为什么实体店生意越来越难做告诉你答案很多小店的商家他们销售价格比生产成本都低很多人不懂他们到底图的是什么其实秘密很简单首先他们入行很早当初的售价也没有这么低比如十块钱生产的东西他卖元包邮这样也会有六元左右的利润等他们赚到钱了销售量也上去了你认为他们会继续卖元赚大钱了吗这就很短视了因为他们生产量提高了那原材料的成本就降低...

PHP-大数据量怎么处理优化 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。如何

中指研究院:上周一线城市整体成交面积环比上涨8.88%,宅地成交量降近八成,广州,一线城市,中指研究院,新建商品住宅

俄称西方在乌武器生产设施将成俄军目标,武器,俄军,英国,乌克兰,俄罗斯,军工企业

红烧肉的做法,红烧肉怎么做请看步骤:1.猪五花切成约2cm左右的块洗净备用2.汤锅做一锅水,凉水下肉3.盖上锅盖,待水开后将肉焯水撇去浮沫后捞出,肉汤保留,捞出的猪五花装盘备用;4.将调料全部准备好5.炒锅倒入适量油,撒入桂皮、八角和草果编出香味...

最近,元宇宙,概念大火,先是Facebook正式更名为,Meta,,专注元宇宙业务,后面又是腾讯注册,QQ元宇宙,商标,巨头公司都开始尝试做,元宇宙,行业方向,那中小企业也不能落伍,普通大众对,元宇宙,一脸懵逼的时候,但有的人已经看到风口,利用元宇宙开始培训赚钱啦,松松团队磊哥最近观察,元宇宙,系列的培训班可火起来了,这就有网友晒出了...。
专为Intel和AMD的新CPU平台定制的Windows7系统,系统集成大量魔改驱动,主要是为个别用户因其它原因必须要安装Win7系统而制作的。

AI,教育领域何时能诞生巨头公司,在真格基金创始人徐小平看来,这个时间似乎近在眼前,2019年4月,在真格基金举办的,教育,AI,沙龙上,徐小平认为未来两到三年里AI,教育领域可能会诞生巨头,不过,AI,教育领域巨头的桂冠花落谁家目前还尚不可知,一批互联网科技巨头却瞅准时机早早进了场,从2018年开始,字节跳动已经推出三款教育品牌,分...。

离创客马拉松·华农站已经过去一个月了,不知道大家对Chaser团队是否还有印象,这个富有文艺气息的团队在创马华农站上初试牛刀,以一个太阳能信息收集站轻松获得了大赛的第三名,Chaser在华农站然而Chaser团队的几位小伙伴对于这个第三名似乎并不满意,于是在创马深大站上,他们带着新的项目——空气吉他卷土重来,一举斩获创客马拉松·深大站...。

记者当天,11月12日,从山东青岛关系部门得知,钢质渔船,鲁青新渔60112,漂浮,已形成2名船员遇难,2人获救,渔船漂浮要素还在调查中,总台记者王伟张明,此前信息...。
